[論文レビュー] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
SWE-benchは、リポジトリ全体のパッチを必要とする2,294件の実世界のGitHub課題を実行ベースで評価するベンチマークである。最先端モデルは最も簡単なタスクしか解けず、oracle retrievedの下でClaude 2は4.8%、GPT-4は1.7%にとどまり、BM25 context retrievalではさらに悪化する。
Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We find real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. To this end, we introduce SWE-bench, an evaluation framework consisting of $2,294$ software engineering problems drawn from real GitHub issues and corresponding pull requests across $12$ popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation tasks. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. The best-performing model, Claude 2, is able to solve a mere $1.96$% of the issues. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
研究の動機と目的
- 大規模言語モデルがGitHubの課題を解決するためにコードベースを実際に編集し、パッチファイルを生成する能力を評価する。
- 複数のPythonリポジトリにわたる多様で長いコンテキストのコード編集タスクを含む、挑戦的で最新のベンチマークを提供する。
- 既存のテストスイートを用いた実行ベースの検証による再現可能な評価フレームワークを提供する。
- オープンな開発を促進するため、トレーニングデータとファインチューニング済みモデルを公開する。
提案手法
- 12の人気PythonリポジトリからSWE-benchを構築し、テストを変更し課題を解決する merged PR に課題をリンクさせる。
- 3段階のパイプライン(リポジトリのスクレイピング、属性フィルタリング、実行ベースのフィルタリング)を経て、2,294件のタスクインスタンスに絞り込む。
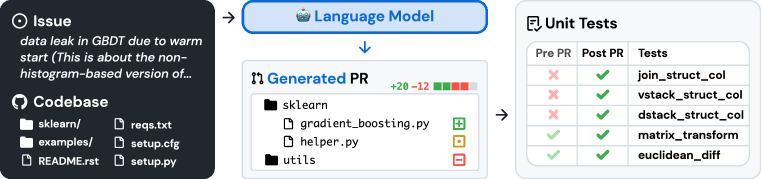
- 課題を課題テキストとコードベースのスナップショットとして表現する。モデルはリポジトリ全体にわたるパッチファイルを生成する。
- パッチを適用してリポジトリのテストを実行することで編集を評価し、パス率を主要指標として測定する。
- 長いコードベース内で関連するコンテキストを提供するために、BM25の疎検索とoracle検索の取得戦略を検討する。
- 37リポジトリからの19,000件の追加の課題-PRペアでLoRAを用いてSWE-Llama 7b/13bをファインチューニングし、競合的なオープンモデルベースラインを作成する。
実験結果
リサーチクエスチョン
- RQ1現在のLMは大規模なコードベースのパッチを生成して実世界のソフトウェア工学上の課題を解決する能力をどの程度持つか?
- RQ2コンテキスト取得戦略とパッチ生成形式がモデルの性能に与える影響はどの程度か?
- RQ3オープンモデルのファインチューニングはリポジトリ規模のコード編集における独自モデルとのギャップを埋められるか?
- RQ4タスクの難度、コンテキスト長、リポジトリの特性はSWE-benchにおけるLMの性能にどのように影響するか?
主な発見
- -most state-of-the-art models fail to solve more than the simplest tasks; Claude 2 achieves 4.8% and GPT-4 1.7% under oracle retrieval.
- BM25-based retrieval further degrades performance (Claude 2 drops to 1.96%).
- Finetuned SWE-Llama models (7b/13b) show limited success and can be sensitive to context distribution shifts.
- Model edits tend to be shorter and simpler than gold patches, often editing fewer lines and files.
- Increasing context length can hurt performance due to difficulty localizing relevant edits within large contexts.
- Even when provided with oracle-retrieved context, models rarely generate correct, well-formatted patch files; about half of generated patches are shorter than gold and fewer edit multiple files.

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。