[論文レビュー] SweetDreamer: Aligning Geometric Priors in 2D Diffusion for Consistent Text-to-3D
SweetDreamerは、2D diffusion幾何 priorsを粗い3D幾何と整合させ、3D-一貫性のあるtext-to-3D結果を実現し、最先端の一貫性を備えた既存のパイプラインへのシームレスな統合を可能にします。
It is inherently ambiguous to lift 2D results from pre-trained diffusion models to a 3D world for text-to-3D generation. 2D diffusion models solely learn view-agnostic priors and thus lack 3D knowledge during the lifting, leading to the multi-view inconsistency problem. We find that this problem primarily stems from geometric inconsistency, and avoiding misplaced geometric structures substantially mitigates the problem in the final outputs. Therefore, we improve the consistency by aligning the 2D geometric priors in diffusion models with well-defined 3D shapes during the lifting, addressing the vast majority of the problem. This is achieved by fine-tuning the 2D diffusion model to be viewpoint-aware and to produce view-specific coordinate maps of canonically oriented 3D objects. In our process, only coarse 3D information is used for aligning. This "coarse" alignment not only resolves the multi-view inconsistency in geometries but also retains the ability in 2D diffusion models to generate detailed and diversified high-quality objects unseen in the 3D datasets. Furthermore, our aligned geometric priors (AGP) are generic and can be seamlessly integrated into various state-of-the-art pipelines, obtaining high generalizability in terms of unseen shapes and visual appearance while greatly alleviating the multi-view inconsistency problem. Our method represents a new state-of-the-art performance with an 85+% consistency rate by human evaluation, while many previous methods are around 30%. Our project page is https://sweetdreamer3d.github.io/
研究の動機と目的
- 2D拡散結果を3Dにリフトする際の多視点不一致を低減する必要性を動機づける。
- コアリティカルな3D幾何と coarse alignment を用いて、2D幾何 priorsを canonical 3D geometriesに整合させる方法を提案する。
- AGPが複数の3D表現とパイプラインへ組み込めることを示す。
- unseenな形状や外観の一般化を維持しつつ、3D一貫性を改善する。
提案手法
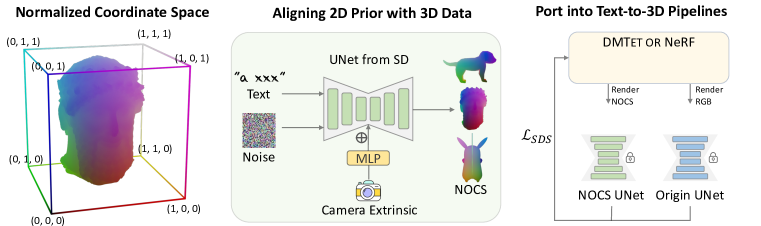
- canonically oriented 3D objectsから viewpoint-conditioned canonical coordinates maps (CCMs)を生成するよう、2D diffusionモデルをファインチューニングする。
- CCMsへキャメラ外部パラメータをMLPを介して条件付けし、コースな3D深度マップを CCMsにレンダリングする。
- VAEによる再エンコード/デコードを行わず、Stable Diffusionの latent-space training setupを用いて CCMsを学習する。
- テキスト〜3Dパイプラインへ coarseな3D priorsを注入し、geometry (SDS losses)を監督する一方で appearance priorsはそのままにする。
- aligned geometry supervision項を追加することで Fantasia3D (DMTet) および DreamFusion (NeRF) パイプラインと統合を実演する。
- Objaverse由来データ(フィルタリング後に270kオブジェクト)と coarseキャンバラ采樣を用いて CCM-conditioned diffusion model을学習する。

実験結果
リサーチクエスチョン
- RQ12D diffusion priorsを canonical 3D geometriesに整合させることは、text-to-3Dリフト時の多視点不一致を減らせるか。
- RQ2幾何 priorsの coarse alignmentは、3D一貫性を向上させつつdiffusionモデルの2D一般化を維持できるか。
- RQ3 AGPを複数の3D表現へ、外観品質を損なうことなく統合するにはどうすべきか。
- RQ4 camera conditioningと CCMsは、さまざまなプロンプトや形状にわたる3D一貫性にどのような影響を与えるか。
- RQ5 AGPは人間が知覚する3D一貫性において、既存のベースラインと比較してどう機能するか。
主な発見
| Method | Cons. Rate ↑ |
|---|---|
| Dreamfusion-IF | 30.0% |
| Magic3D-IF | 35.0% |
| TextMesh-IF | 23.8% |
| SJC | 7.5% |
| Fantasia3D | 32.5% |
| Ours (DMTet-based) | 87.5% |
| Ours (NeRF-based IF) | 88.8% |
- AGPは2つのパイプラインで85%以上の人間評価一貫性率という最先端の3D一貫性を達成する。
- AGPベースの手法は、 DreamFusion-IF、 Magic3D-IF、 TextMesh-IF、 SJC、 Fantasia3Dなどのベースラインと比較して一貫性で大幅に上回る。
- 訓練は粗い3D幾何マップのみを使用し、高忠実度の3D外観データへの強い依存を回避する。
- AGPは複数の3D表現(DMTetとNeRF)と互換性があり、追加の監督ブランチとして統合可能。
- このアプローチは、未見の形状や外観に対する2D diffusionモデルの豊かな生成能力を保持する。
- ユーザ調査は、3D一貫性の観点でAGP対応結果をベースラインより強く支持する傾向を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。