[論文レビュー] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer は階層的な vision Transformer を shift windows で導入し、線形計算量を達成し、画像分類、物体検出、意味セグメンテーション全般で優れた結果を得ています。
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with extbf{S}hifted extbf{win}dows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures. The code and models are publicly available at~\url{https://github.com/microsoft/Swin-Transformer}.
研究の動機と目的
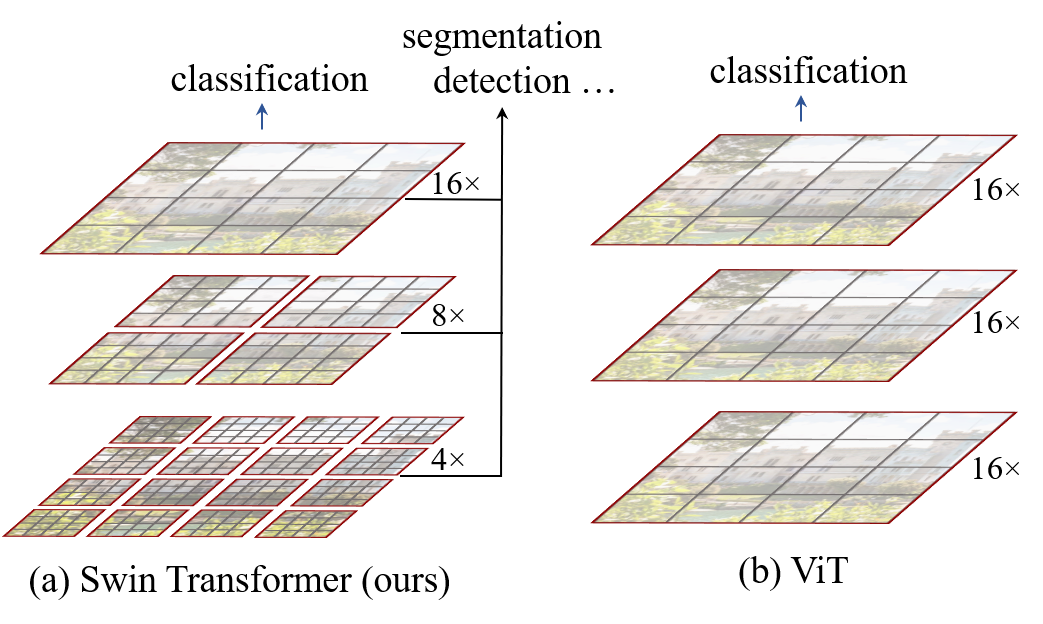
- マルチスケールの視覚的事象を扱える、視覚用の汎用 Transformer バックボーンを開発する。
- 局所的なウィンドウ付き自己注意により、画像サイズに対して線形な計算量を達成する。
- FPN/ U-Net スタイルと互換性を持つ dense prediction タスクをサポートする階層的な特徴マップを実現する。
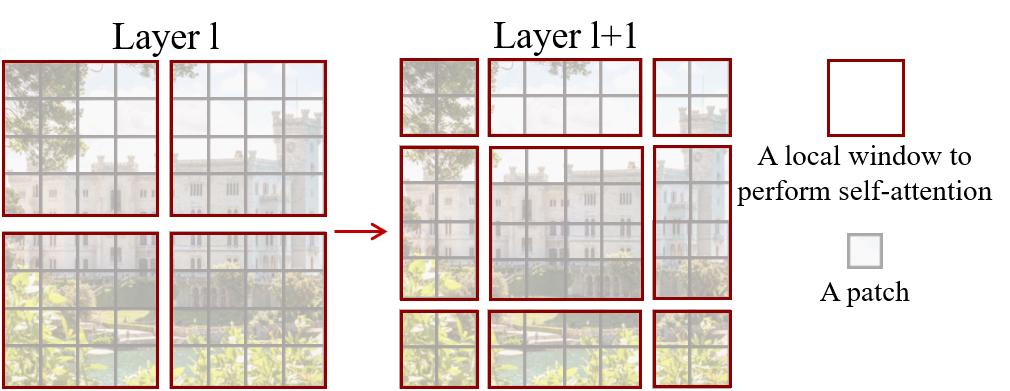
- ずらしたウィンドウ分割を通じて層間のウィンドウを橋渡しし、モデリング能力を高める。
提案手法
- 画像をパッチトークンに分割し、それらを線形に埋め込み、階層的なステージを形成する。
- 非重複ウィンドウ内で局所的に自己注意を計算し、線形の複雑さを達成する。
- 連続するブロック間で shifted window 戦略を適用して、窓間の接続を可能にする。
- 自己注意に相対位置バイアスを用いて空間モデリングを改善する。
- W-MSAとSW-MSAを組み合わせた Swin Transformer ブロックを構築し、GELU と残差接続を備えたMLPを続ける。
- 指定されたステージ構成で複数のモデルサイズ(Swin-T/Swin-S/Swin-B/Swin-L)を提供する。
実験結果
リサーチクエスチョン
- RQ1shifted window 自己注意を用いた階層型 Transformer は、分類と密な視覚タスクの両方に対して一般的なバックボーンとして機能し得るか?
- RQ2層間でウィンドウ分割をシフトすることは、許容できる遅延で窓間の接続を提供するか?
- RQ3Swin Transformer は ImageNet-1K、COCO の物体検出/インスタンス分割、ADE20K のセマンティック分割において、最新のバックボーンと比較してどのように性能を発揮するか?
主な発見
- Swin-T は ImageNet-1K のトップ1 81.3% を通常の訓練で達成し、ImageNet-22K の事前学習により Swin-B/L はそれぞれ 86.4%/87.3% へスケールする。
- COCO test-dev では Swin-T/B-L が従来の最先端を最大で +2.7 box AP および +2.6 mask AP 上回る。
- ADE20K val では Swin-S/L がそれぞれ prior best モデルより +5.3 mIoU および +3.2 mIoU を達成。
- Swin Transformer は、分類、検出、分割タスクで、類似のレイテンシーを持つ DeiT および ResNeXt/ResNet バックボーンを大幅に上回る。
- ずらした窓設計は、実質的なモデリング効果をもたらしつつ遅延増加は控えめで、相対位置バイアスはタスク全体の性能を向上させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。