[論文レビュー] SyncDreamer: Generating Multiview-consistent Images from a Single-view Image
SyncDreamerは、3D対応の特徴注意機構を備えた同期的なマルチビューディフュージョンを用いて、1つの入力ビューからマルチビューで一貫した画像を生成し、ビュー間の不整合を生じない高精度な3D再構成を実現する。
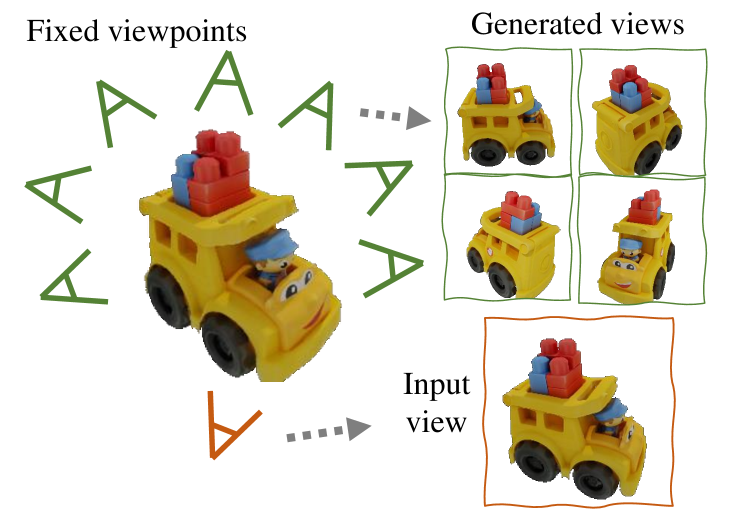
In this paper, we present a novel diffusion model called that generates multiview-consistent images from a single-view image. Using pretrained large-scale 2D diffusion models, recent work Zero123 demonstrates the ability to generate plausible novel views from a single-view image of an object. However, maintaining consistency in geometry and colors for the generated images remains a challenge. To address this issue, we propose a synchronized multiview diffusion model that models the joint probability distribution of multiview images, enabling the generation of multiview-consistent images in a single reverse process. SyncDreamer synchronizes the intermediate states of all the generated images at every step of the reverse process through a 3D-aware feature attention mechanism that correlates the corresponding features across different views. Experiments show that SyncDreamer generates images with high consistency across different views, thus making it well-suited for various 3D generation tasks such as novel-view-synthesis, text-to-3D, and image-to-3D.
研究の動機と目的
- 任意の物体に対して、単一ビューからマルチビュー3D再構成を堅牢に導入・実現できるよう、動機づけと実現を図る。
- 共同のマルチビュー拡散モデルを用いて、生成画像のマルチビュー間の不整合を克服する。
- デノイジング時に視点横断情報を同期する3D対応の特徴注意機構を活用する。
- 多様な入力スタイルに対する一般化を維持するため、事前学習済みの2D拡散モデルから初期化する。
提案手法
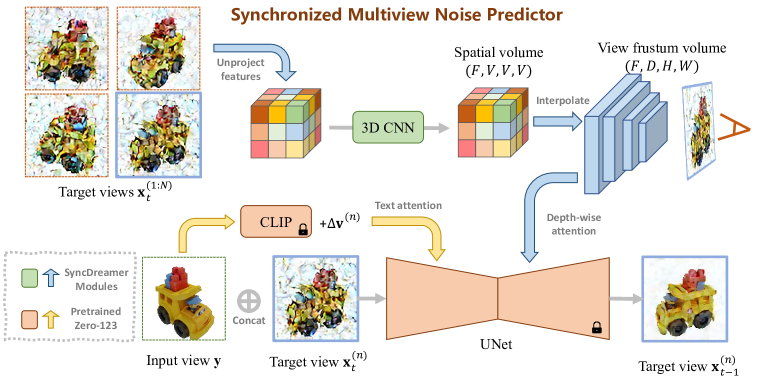
- N個の同期ノイズ予測子を用いて、Nビューの結合分布をモデル化するよう拡散モデルを拡張する。
- Zero123(Stable Diffusionベース)から初期化された共有のUNetを全ビューのバックボーンとして使用する。
- 3D対応の特徴注意を導入し、グローバルな空間ボリュームから導出されたビュー・フラスタム上に深さ方向の注意機構を構築する。
- 各ステップでランダムに選択したビューのノイズを予測する損失で学習し、ビュー間の同期を可能にする。
- 固定されたビュー集合をレンダリングする(N = 16)とObjaverseデータで学習して跨ビューの一貫性を学習する。
実験結果
リサーチクエスチョン
- RQ1 diffusionプロセスは、単一の入力画像からの跨ビュー一貫性を保証するために、複数ビューを共同でモデル化・同期するよう拡張できるか。
- RQ2デノイジング中に跨ビュー情報をどのように符号化・伝播させて、幾何学と色の一貫性をビュー間で強制できるか。
- RQ3強力な2D拡散バックボーン(Zero123)から初期化することは、3D再構成の任意オブジェクトおよび入力スタイルへの一般化を向上させるか。
- RQ43D対応の注意機構は、マルチビューの一貫性と下流の3D再構成品質にどのような影響を与えるか。
主な発見
| 指標 | RealFusion | Zero123 | 我々の手法 |
|---|---|---|---|
| NVS - PSNR | 15.26 | 18.93 | 20.05 |
| NVS - SSIM | 0.722 | 0.779 | 0.798 |
| NVS - LPIPS | 0.283 | 0.166 | 0.146 |
| NVS - #Points | 4010 | 95 | 1123 |
| SVR - Chamfer Dist. | 0.0819 | 0.0339 | 0.0261 |
| SVR - Volume IoU | 0.2741 | 0.5035 | 0.5421 |
- SyncDreamerは、Google Scanned Objectデータセット上でベースラインよりも高いマルチビューの一貫性と再構成品質を実現する。
- 新規ビュー合成において、RealFusion、Zero123、SyncDreamerはそれぞれPSNR/SSIM/LPIPSが15.26/0.722/0.283、18.93/0.779/0.166、20.05/0.798/0.146となり、#Pointsは4010、95、1123。
- 単一ビュー再構成では、SyncDreamerはChamfer Distance 0.0261およびVolume IoU 0.5421を達成し、RealFusion(0.0819, 0.2741)およびZero123(0.0339, 0.5035)を上回る。
- 同じ入力からシードを変えることで複数の妥当な実例を生成できる。
- アブレーションにより、3D対応の注意機構の必須性と、2Dスタイルおよび図画の一般化のためにZero123をバックボーンとして使用することの重要性が示される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。