[論文レビュー] Synthetic Data Generation with LLM for Improved Depression Prediction
本論文は、DAIC-WOZの文字起こしから合成の要約と感情データを生成するためのチェーンオブソート prompting パイプラインを提案します。実データを拡張してうつ病の重症度予測を改善しつつ、プライバシーとデータの不均衡に対処します。
Automatic detection of depression is a rapidly growing field of research at the intersection of psychology and machine learning. However, with its exponential interest comes a growing concern for data privacy and scarcity due to the sensitivity of such a topic. In this paper, we propose a pipeline for Large Language Models (LLMs) to generate synthetic data to improve the performance of depression prediction models. Starting from unstructured, naturalistic text data from recorded transcripts of clinical interviews, we utilize an open-source LLM to generate synthetic data through chain-of-thought prompting. This pipeline involves two key steps: the first step is the generation of the synopsis and sentiment analysis based on the original transcript and depression score, while the second is the generation of the synthetic synopsis/sentiment analysis based on the summaries generated in the first step and a new depression score. Not only was the synthetic data satisfactory in terms of fidelity and privacy-preserving metrics, it also balanced the distribution of severity in the training dataset, thereby significantly enhancing the model's capability in predicting the intensity of the patient's depression. By leveraging LLMs to generate synthetic data that can be augmented to limited and imbalanced real-world datasets, we demonstrate a novel approach to addressing data scarcity and privacy concerns commonly faced in automatic depression detection, all while maintaining the statistical integrity of the original dataset. This approach offers a robust framework for future mental health research and applications.
研究の動機と目的
- テキスト由来のうつ病検出におけるデータ不足とプライバシー問題を、合成データの生成で解決する。
- depression score を条件にした二段階の要約および感情分析生成プロセスを開発する。
- 合成データの忠実度、有用性、プライバシーを評価してうつ病重症度予測の改善を測る。
提案手法
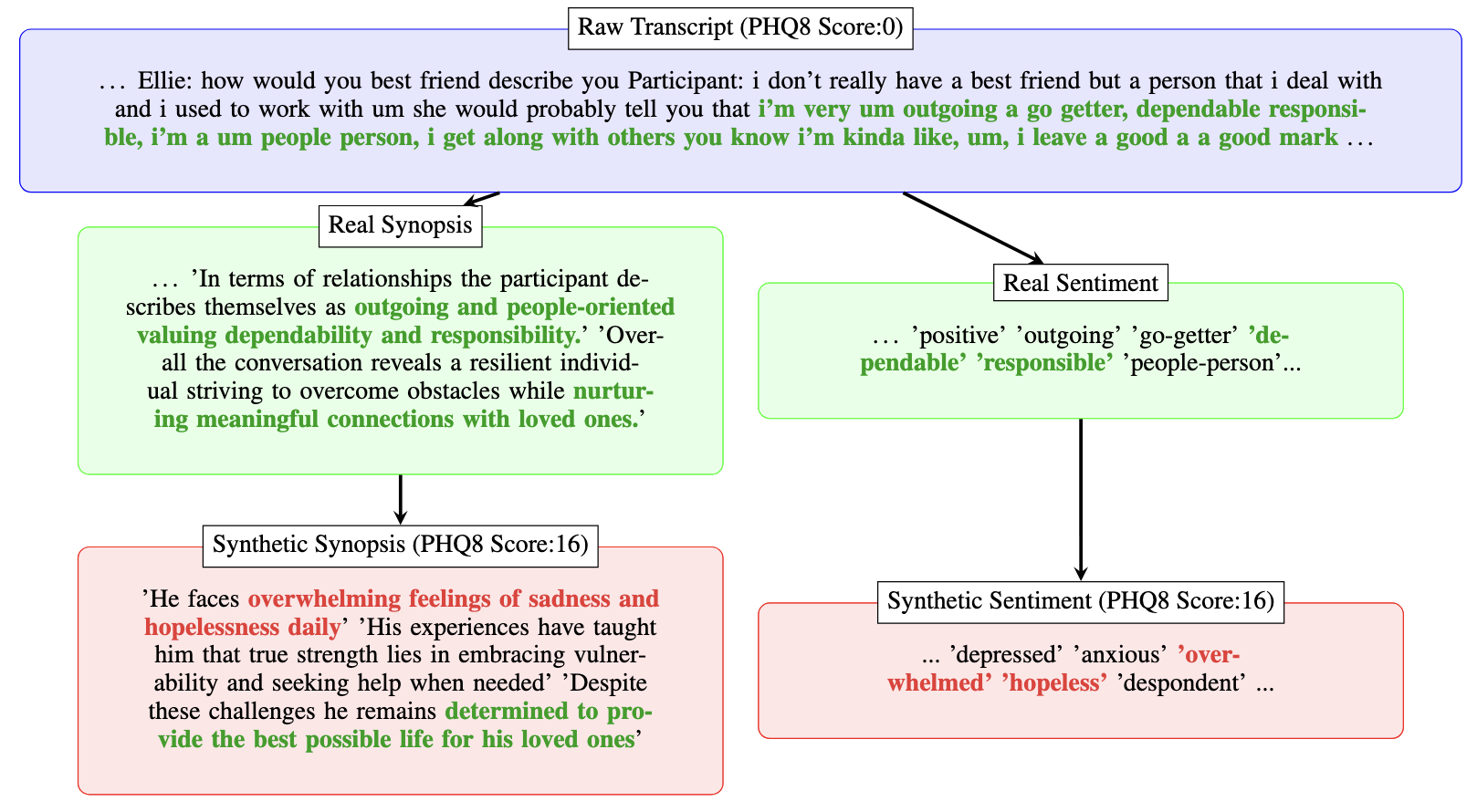
- 元の転写から初期の要約と感情分析を生成するために Meta Llama 3.2-3B-Instruct を使用する。
- コーチングの思考プロンプトを適用して、新しくランダムに生成された PHQ-8 スコアに対する合成要約と感情分析を作成する。
- 合成データの偏りを減らすために、PHQ-8 スコアが高いケースをオーバーサンプリングしてデータ分布を平準化する。
- 合成データでモデルを訓練し、その後実データと組み合わせて性能向上を評価する。
- 合成データと実データの埋め込み距離指標でプライバシーを評価し、要約埋め込みの PCA で忠実度を可視化する。
実験結果
リサーチクエスチョン
- RQ1チェーンオブソート prompting によって生成された合成データは、実データに追加することでうつ病の重症度予測を改善できるか。
- RQ2要約ベースの合成転写は元のデータの主要な統計特性(忠実度)を保持し、参加者のプライバシーを保護するか。
- RQ3合成データは、実データのみで訓練したモデルと比較してモデル訓練にどのような影響を与えるか。
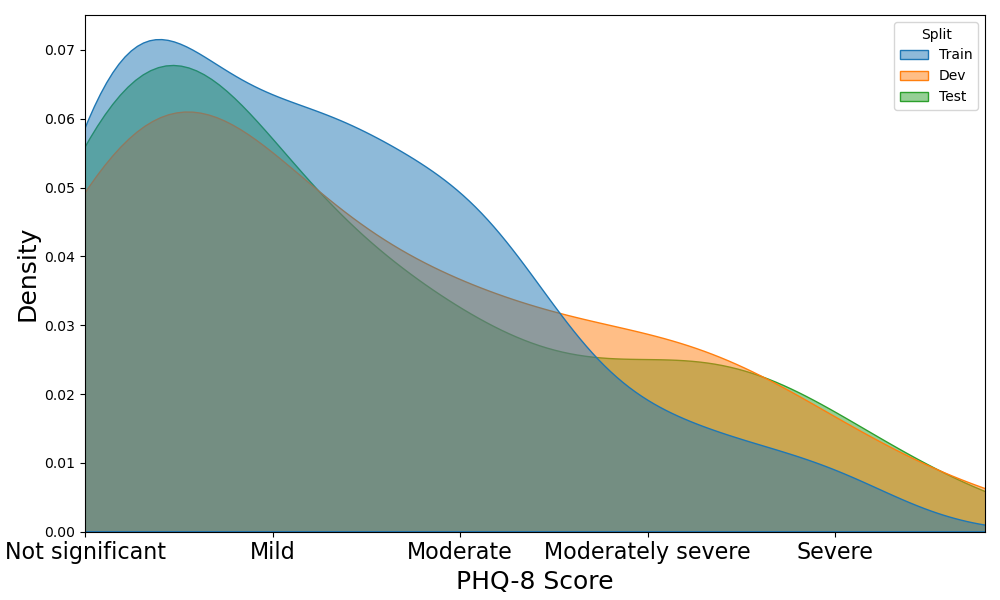
- RQ4PHQ-8 のスコア分布の不均衡を扱う際、合成サンプルによるデータ拡張はどの程度効果的か。
主な発見
- 合成データだけで PHQ-8 スコア予測の RMSE が 4.80、MAE が 4.06 を達成し、いくつかの実データベースよりも良好。
- 元データと合成データを組み合わせると RMSE が 4.64、MAE が 3.66 と最良の結果を示す。
- この設定では BERT モデルが Random Forest および GPT-4o のベースラインよりも優れている。
- 要約埋め込みの PCA は、元データと合成データの重なりを示し、合成データが深刻なうつ病領域へ拡大する。
- プライバシー分析では Real vs. Synthetic の埋め込み距離の平均が Real vs. Real より大きく、実データからの乖離が大きく、プライバシー保護が改善されることを示唆。
- 合成データはデータの多様性を高め、PHQ-8 スコア分布のバランスを改善してモデル性能の向上に寄与する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。