[論文レビュー] T-RAG: Lessons from the LLM Trenches
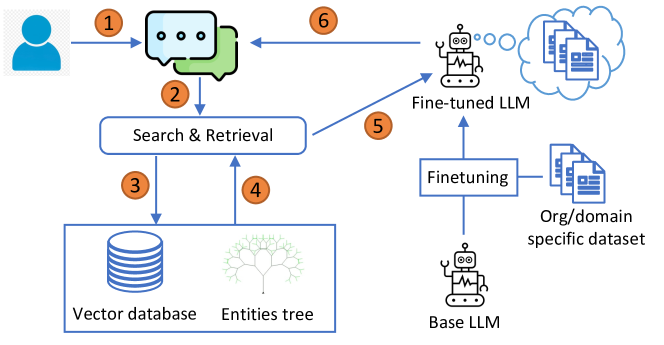
本論文はTree-RAG(T-RAG)を提案する。これは階層的エンティティツリーと私有ガバナンス文書のオンプレミスQAのための finetuned Llama-2 7B を活用した検索 augmented 生成システムで、標準のRAGやファインチューニング済みベースラインより精度が向上し、教訓を得た。
Large Language Models (LLM) have shown remarkable language capabilities fueling attempts to integrate them into applications across a wide range of domains. An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, limited computational resources and the need for a robust application that correctly responds to queries. Retrieval-Augmented Generation (RAG) has emerged as the most prominent framework for building LLM-based applications. While building a RAG is relatively straightforward, making it robust and a reliable application requires extensive customization and relatively deep knowledge of the application domain. We share our experiences building and deploying an LLM application for question answering over private organizational documents. Our application combines the use of RAG with a finetuned open-source LLM. Additionally, our system, which we call Tree-RAG (T-RAG), uses a tree structure to represent entity hierarchies within the organization. This is used to generate a textual description to augment the context when responding to user queries pertaining to entities within the organization's hierarchy. Our evaluations, including a Needle in a Haystack test, show that this combination performs better than a simple RAG or finetuning implementation. Finally, we share some lessons learned based on our experiences building an LLM application for real-world use.
研究の動機と目的
- 民間組織文書向けの実世界のLLMベースQAシステムを実証する。
- RAGとファインチューニング済みのオープンソースLLMを組み合わせることで事実的正確性と応答品質が向上することを示す。
- エンティティ階層を用いた木構造のコンテキストを導入し、エンティティ関連の質問への応答を補強する。
- 正確であるが過度に冗長な回答を捉える新しい評価指標(Correct-Verbose)を提案する。
- 本番環境でのLLM搭載QAシステムの導入から得られた実践的な教訓を共有する。
提案手法
- 回答生成のためにRetrieval-Augmented Generation (RAG)とファインチューニング済みのオープンソースLlama-2 7Bを組み合わせる。
- Tree-RAG (T-RAG)を導入する:標準のRAGコンテキストを、組織階層を符号化するエンティティツリーで補強する。
- 組織のガバナンス文書から指示データセットを生成し、4-bit量子化を用いたPEFT(QLoRA)を実行してLLMをファインチューニングする。
- 文書チャンクのベクターストア(Chroma DB)を使用し、MM Retrievalで多様かつ関連性の高いチャンクを選択する。
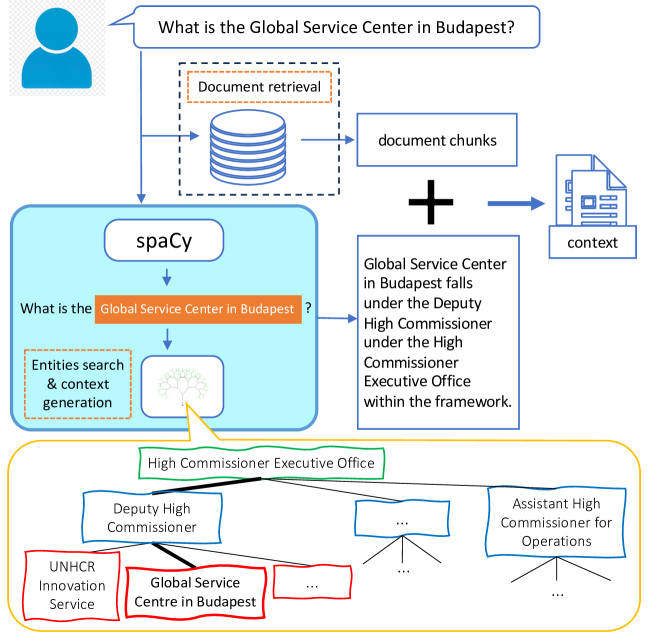
- クエリ内で見つかったエンティティに関するテキスト表現を、カスタム組織固有ルールを用いたspaCyベースのNERで補足して取得済みコンテキストを拡張する。
- 組織の階層を木として表現し、エンティティが言及されたときに文脈を補強するためにエンティティのポジション情報を抽出するためにそれをクエリする。
- 正確さ(C)と正確-冗長性(CV)回答についての人間評価で評価する。
実験結果
リサーチクエスチョン
- RQ1T-RAGシステムは、企業文書QAにおいて標準のRAGまたはファインチューニングモデル単独と比較して事実的正確性と関連性を改善するか。
- RQ2エンティティツリーのコンテキストを追加することは、特に複雑なエンティティ関連の質問で性能にどのような影響を与えるか。
- RQ3コンテキストが限られている場合やエンティティ階層が活用される場合、ファインチューニング済みLLMとRAGの比較はどうなるか。
- RQ4提案されたCorrect-Verbose指標は、システム間の意味のある差別化を提供するか。
主な発見
| 質問セット | N | C | CV | T | 割合 | |
|---|---|---|---|---|---|---|
| RAG | set 1 | 17 | 9 | 0 | 9 | 52.9% |
| RAG | set 2 | 11 | 7 | 0 | 7 | 63.6% |
| RAG | set 3 | 9 | 4 | 1 | 5 | 55.6% |
| RAG | All | 37 | 20 | 1 | 21 | 56.8% |
| Finetuned | set 1 | 17 | 11 | 1 | 12 | 70.6% |
| Finetuned | set 2 | 11 | 3 | 0 | 3 | 27.3% |
| Finetuned | set 3 | 9 | 5 | 0 | 5 | 55.6% |
| Finetuned | All | 37 | 19 | 1 | 20 | 54.1% |
| T-RAG | set 1 | 17 | 9 | 4 | 13 | 76.5% |
| T-RAG | set 2 | 11 | 6 | 2 | 8 | 72.7% |
| T-RAG | set 3 | 9 | 6 | 0 | 6 | 66.7% |
| T-RAG | All | 37 | 21 | 6 | 27 | 73.0% |
- T-RAGはRAG(21/37)またはFinetuned(20/37)よりも高い全体的な正解または正解-冗長(CV)回答を達成する(27/37)。
- エンティティ関連の質問の正確性は、特に複雑なクエリに対して、ツリーコンテキストによって大幅に向上する。
- エンティティツリーコンテキストをファインチューニング済みLlama-2と組み合わせると顕著な利得が得られる(例:単純な質問は8/17から17/17へ;複雑な質問は8/22から15/22へ)。
- RAGがエンティティツリーコンテキストを持つ場合、組織カテゴリ内でのエンティティの幻影や不整合を減少させる。
- T-RAGはより冗長な正解(CV)を示すが、全体として質問セット全体で正確性が高い。
- 評価は3つのユーザー質問セットと人間が評価した回答(CまたはCV)を用いて実施された。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。