[論文レビュー] Tag-LLM: Repurposing General-Purpose LLMs for Specialized Domains
Tag-LLM は、一般的な LLM を専門分野へ適応させるために、ドメイン入力タグと機能入力タグを学習可能な埋め込みとして導入します。これによりゼロショット一般化を実現し、NLP 翻訳や非言語的タスク(タンパク質/SMILES 性質予測および薬剤-標的結合親和性など)で競争力のあるまたは優れた性能を発揮します。
Large Language Models (LLMs) have demonstrated remarkable proficiency in understanding and generating natural language. However, their capabilities wane in highly specialized domains underrepresented in the pretraining corpus, such as physical and biomedical sciences. This work explores how to repurpose general LLMs into effective task solvers for specialized domains. We introduce a novel, model-agnostic framework for learning custom input tags, which are parameterized as continuous vectors appended to the LLM's embedding layer, to condition the LLM. We design two types of input tags: domain tags are used to delimit specialized representations (e.g., chemical formulas) and provide domain-relevant context; function tags are used to represent specific functions (e.g., predicting molecular properties) and compress function-solving instructions. We develop a three-stage protocol to learn these tags using auxiliary data and domain knowledge. By explicitly disentangling task domains from task functions, our method enables zero-shot generalization to unseen problems through diverse combinations of the input tags. It also boosts LLM's performance in various specialized domains, such as predicting protein or chemical properties and modeling drug-target interactions, outperforming expert models tailored to these tasks.
研究の動機と目的
- 一般用途の LLM が専門分野で十分に機能しない理由を動機づけ、完全なファインチューニングを伴わずに LLM を条件付けする再利用可能なタグ付けフレームワークを提案する。
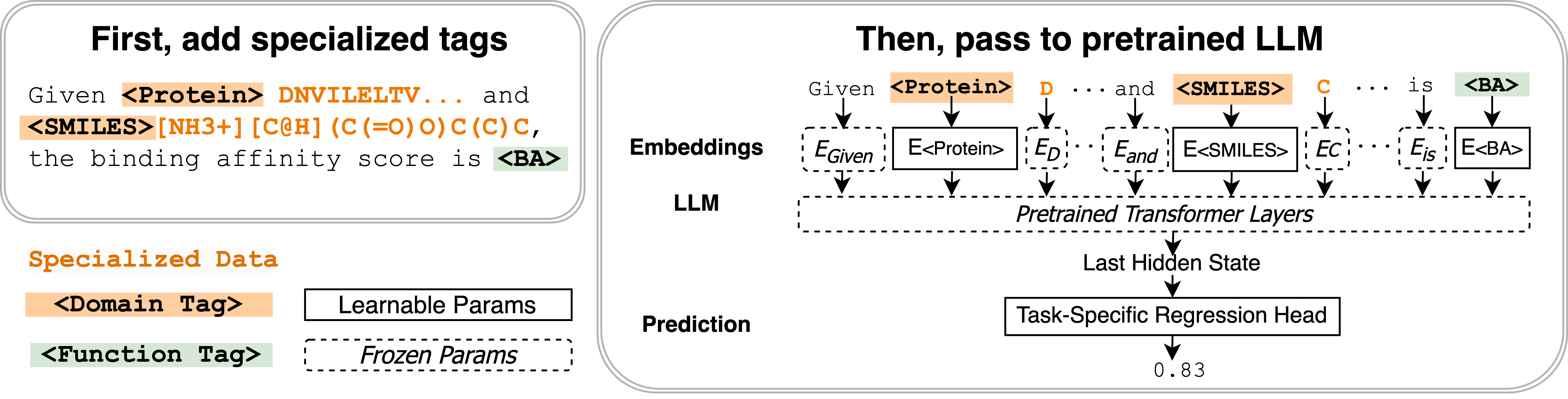
- ドメインタグと機能タグという2種類の学習可能な入力タグを、LLM の入力に埋め込むパラメータとして導入する。
- 補助的な同一ドメインデータとドメイン知識を用いて、ドメインタグと機能タグを学習する三段階のトレーニングプロトコルを開発する。
- ゼロショット一般化と多言語翻訳、非言語的タスク(タンパク質、SMILES、薬剤開発)における競争力のある性能を示す。
- Tag-LLM のモデル非依存性とプラグアンドプレー性、および新しいドメインやタスクに対するスケーラビリティを強調する。
提案手法
- ドメインデータを境界づけ、ドメインレベルの情報を符号化するドメインタグと、タスクの意味を符号化し、ドメインを跨いで共有可能な機能タグの2種類のタグを定義する。
- 各タグを、語彙全体の平均トークン埋め込みから初期化された学習可能な p-by-d 埋め込み行列として表現し、LLM の埋め込み空間に追加する。
- 三段階のトレーニングプロトコル:(Stage 1)ラベルなしの同一ドメインデータ上で次の単語予測を用いてドメインタグを訓練;(Stage 2)ラベル付きデータを用いて、入力にドメインタグを埋め込んだ状態で単一ドメイン機能タグを訓練;(Stage 3)複数ドメインタグを用いてクロスドメイン機能タグを訓練し、共有能力を学習する。
- 数値予測タスクを改善するために、非テキスト出力(例:スカラー予測)用の回帰ヘッドを機能タグに拡張する。
- モジュール化された階層的タグ付けフレームワークを採用し、段階的なタグ追加と構成的問題解決を可能にする。
実験結果
リサーチクエスチョン
- RQ1未見のドメイン-タスク組み合わせに対するゼロショット一般化を、学習可能な入力タグのモジュール式セットが可能にするか。
- RQ2ドメインタグと機能タグは、ドメイン知識とタスク指示を切り離して、標準的なプロンプトチューニングより性能を向上させるか。
- RQ3Tag-LLM は、多言語翻訳および非言語的科学タスク(タンパク質、SMILES、薬剤発見)において、ドメイン特化ベースラインまたは一般ベースラインと比べてどうか。
- RQ4タグの長さ、エンリッチメント、回帰ヘッドの含有が予測精度に与える影響はどの程度か。
- RQ5モデル非依存のタグ付けフレームワークは、最小限のラベル付きデータで新しいドメインやタスクへスケール可能か。
主な発見
- ドメインタグは、専門データ向けのコンテキスト切替機として効果的である。
- 1つの共有機能タグで複数のドメインをサポートし、異なるタスクに対応できる。
- Tag-LLM は、見たドメインと見ないドメイン-タスクの組み合わせに対しても、競争力のある多言語翻訳性能を達成する。
- Tag-LLM は、いくつかの薬剤発見データセットで最先端の結果を達成し、しばしばベースライン PEFT 手法を上回る。
- ドメインタグをタスク関連知識で豊富化すると性能が向上し、回帰ヘッドは非テキスト出力および数値予測に寄与する。
- このアプローチは、ドメインと機能タグの組み合わせを通じて、未見の問題へゼロショット一般化を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。