[論文レビュー] Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
Step-Back Prompting は抽象化を用いて高次の概念と第一原理を導出し、推論を現実化して STEM、Knowledge QA、そしてマルチホップ推論のマルチタスク性能を向上させ、ベースラインおよび CoT プロンプティングより顕著な向上を達成します。
We present Step-Back Prompting, a simple prompting technique that enables LLMs to do abstractions to derive high-level concepts and first principles from instances containing specific details. Using the concepts and principles to guide reasoning, LLMs significantly improve their abilities in following a correct reasoning path towards the solution. We conduct experiments of Step-Back Prompting with PaLM-2L, GPT-4 and Llama2-70B models, and observe substantial performance gains on various challenging reasoning-intensive tasks including STEM, Knowledge QA, and Multi-Hop Reasoning. For instance, Step-Back Prompting improves PaLM-2L performance on MMLU (Physics and Chemistry) by 7% and 11% respectively, TimeQA by 27%, and MuSiQue by 7%.
研究の動機と目的
- 大規模言語モデルにとって、複雑で詳細な推論の課題を動機づける。
- 問題を解く前に高レベルの抽象を導出する Step-Back Prompting を提案する。
- 抽象化にguided 推論が STEM、知識 QA、マルチホップタスクの精度を向上させることを示す。
提案手法
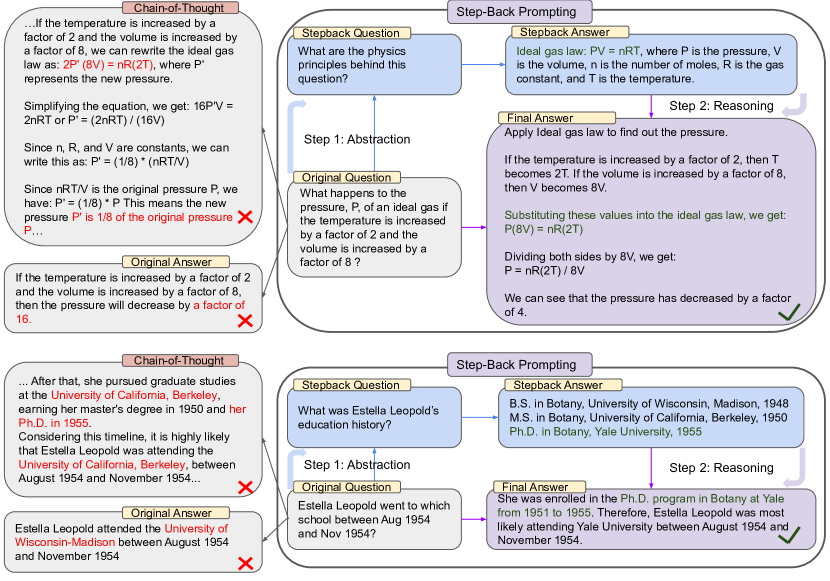
- Two-step Abstraction-and-Reasoning: まず高レベルの概念や原理を導出し、次にこれらの抽象化を基に解法を grounding する。
- Few-shot デモンストレーションを用いて LLM に抽象化ステップを教える。
- 必要に応じて高レベルの概念を補足事実で grounding する Retrieval Augmentation (RAG) を活用する。
- Greedy decoding と予測のスコアリングベースの評価で、STEM、Knowledge QA、Multi-Hop の多様なデータセットを評価する。
- PaLM-2L および GPT-4 を CoT、TDB、RAG を適用可能な範囲で含むベースラインと比較する。
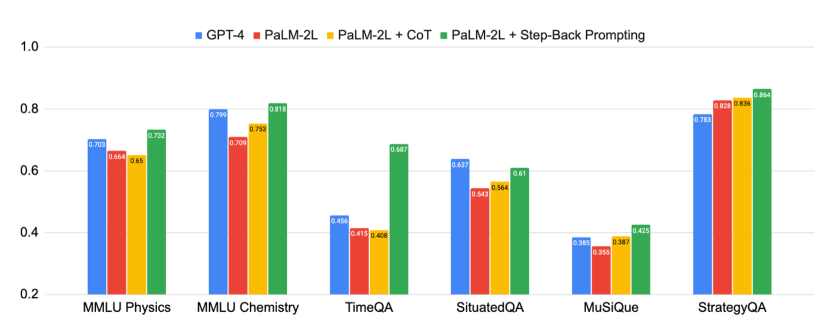
実験結果
リサーチクエスチョン
- RQ1Step-Back Prompting は標準プロンプティングおよび Chain-of-Thought プロンプティングと比較して STEM、Knowledge QA、Multi-Hop タスクの精度を向上させるか?
- RQ2抽象化ステップはデモンストレーションの数に対してどれくらい堅牢か?
- RQ3抽象化ガイド推論によって影響を受けやすいエラーのタイプは何か(推論、計算、文脈喪失など)?
主な発見
- Step-Back Prompting は MMLU Physics で PaLM-2L の性能を 7 ポイント、MMLU Chemistry で 11 ポイント改善し、両サブタスクで GPT-4 を上回る。
- Step-Back Prompting は TimeQA で 27%、MuSiQue で PaLM-2L のベースラインよりそれぞれ 7% 改善。
- 全タスクを通じて、Step-Back は CoT および TDB を最大 36% 上回る分析があり、ベースモデルのエラーの substantial portion を修正(最大約 40%)、新たなエラーの割合は約 12%。
- アブレーションにより、Step-Back は few-shot デモの数に対して堅牢で、抽象化を教えるのに通常は1つの例で十分であることが示された。
- エラー分析は、残る多くのエラーが Abstraction ステップより Reasoning ステップで発生することを示しており、Reasoning が主要なボトルネックであることを強調している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。