[論文レビュー] TDN: Temporal Difference Networks for Efficient Action Recognition
本稿では、時間的差分モジュール(TDM)を用いてマルチスケールの動きパターンを捉える、軽量で効率的な動画行動認識フレームワークである時系列差分ネットワーク(TDN)を提案する。局所的(連続フレーム)およびグローバル的(セグメントレベル)なスケールで時間的差分を適用することにより、最小限の計算コストで行動認識の精度を向上させ、Something-Something V1/V2 で新たな最先端性能を達成するとともに、Kinetics-400 でも競争力ある性能を示した。
Temporal modeling still remains challenging for action recognition in videos. To mitigate this issue, this paper presents a new video architecture, termed as Temporal Difference Network (TDN), with a focus on capturing multi-scale temporal information for efficient action recognition. The core of our TDN is to devise an efficient temporal module (TDM) by explicitly leveraging a temporal difference operator, and systematically assess its effect on short-term and long-term motion modeling. To fully capture temporal information over the entire video, our TDN is established with a two-level difference modeling paradigm. Specifically, for local motion modeling, temporal difference over consecutive frames is used to supply 2D CNNs with finer motion pattern, while for global motion modeling, temporal difference across segments is incorporated to capture long-range structure for motion feature excitation. TDN provides a simple and principled temporal modeling framework and could be instantiated with the existing CNNs at a small extra computational cost. Our TDN presents a new state of the art on the Something-Something V1 & V2 datasets and is on par with the best performance on the Kinetics-400 dataset. In addition, we conduct in-depth ablation studies and plot the visualization results of our TDN, hopefully providing insightful analysis on temporal difference modeling. We release the code at https://github.com/MCG-NJU/TDN.
研究の動機と目的
- 動画行動認識における効率的で効果的な時間的モデリングの課題に取り組む。
- 光流や高コストな3D畳み込みに依存せずに、時間的差分を用いて外観と動きを統合的に捉える、統一的かつエンドツーエンドで学習可能なフレームワークを設計する。
- 二段階の差分モデリングパラダイムを通じて、短期的および長期的動きモデリングを体系的に調査する。
- 標準的な2D CNNに軽量な時間的差分モジュールを統合することで、計算コストを低く抑えながら高い精度を達成する。
- アブレーションおよび可視化研究を通じて、時間的差分に基づく動きモデリングに関する洞察を提供する。
提案手法
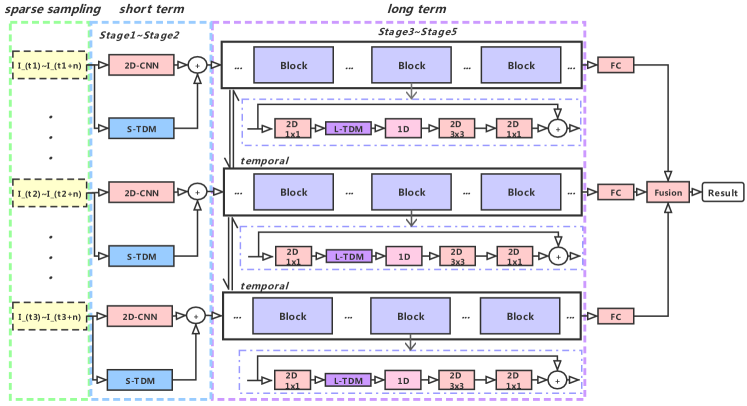
- 連続フレーム間の差分を計算することで、細粒度の動きパターンを抽出する局所的モデリング用の時間的差分モジュール(TDM)を導入する。
- セグメント全体にわたるマルチスケールで双方向の差分モジュールを用いて、長期的な時間的構造を捉え、グローバルな動きの強化を実現する。
- 二段階の差分モデリング戦略を採用:局所的差分でフレームレベルの動きを、グローバル的差分でセグメントレベルの動きを捉える。
- 横方向接続を適用して時間的差分特徴を2D CNNに統合し、パラメータ増加を最小限に抑えながらエンドツーエンド学習を可能にする。
- 包括的およびスパースなサンプリングを用いて、動画全体にわたる時間的情報を効率的に抽出する。
- Grad-CAMを用いて可視化を行い、TDMの注釈メカニズムを分析・検証する。
![Figure 1: Video classification performance comparison on Something-Something V1 [ 8 ] in terms of Top1 accuracy, computational cost, and model size. Our proposed TDN achieves the best trade-off between accuracy and efficiency, when compared with previous methods such as NL I3D [ 40 ] , ECO [ 46 ] ,](https://ar5iv.labs.arxiv.org/html/2012.10071/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1時間的差分演算は、動画認識における動きモデリングにおいて、光流や3D畳み込みの代わりに有効に機能するか?
- RQ2局所的差分モデリングとグローバル的差分モデリングの違いは、行動認識性能にどのように影響するか?
- RQ3二段階の差分モデリングフレームワークは、マルチスケールの動きパターンを捉える上で果たす貢献は何か?
- RQ4TDMは特徴活性化マップおよびモデルの解釈性にどのように影響を与えるか?
- RQ5既存の最先端手法と比較して、TDNの計算効率はどの程度か?
主な発見
- UCF101 では新しい最先端のトップ1精度 97.4%、HMDB51 では 76.3% を達成し、TSM、I3D、S3D などの先行手法を上回った。
- Something-Something V1 データセットでは、精度と効率のバランスが最も優れており、NL I3D、ECO、TSM などの手法を上回った。
- Tesla V100 上で1動画あたり 22.1 ms(約 45.2 FPS)で実行され、一部のベースラインより遅延が高めであるが、リアルタイム推論を達成した。
- アブレーションスタディの結果、時間的差分演算が性能向上に顕著に寄与しており、S-TDM と L-TDM が局所的およびグローバルな動きモデリングに寄与していることが確認された。
- Grad-CAMによる可視化では、TDM を搭載したTDN がベースラインよりも動きに関連する領域に注目していることが示され、特徴学習の向上が裏付けられた。
- 本手法は一般化性能が高く、Kinetics-400 から UCF101 や HMDB51 などの小さなデータセットへの転移が効果的に機能し、特に動きの多い HMDB51 で顕著な向上が得られた。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。