[論文レビュー] Temporal Perceiving Video-Language Pre-training
TemPVLは、短い映像とテキストストリームを長いシーケンスに統合して、時系列アノテーションなしで微細で時間的に意識したクロスモーダル整合を学習するテキスト-動画局在化事前学習タスクを導入し、複数の動画言語タスクの性能を向上させる。
Video-Language Pre-training models have recently significantly improved various multi-modal downstream tasks. Previous dominant works mainly adopt contrastive learning to achieve global feature alignment across modalities. However, the local associations between videos and texts are not modeled, restricting the pre-training models' generality, especially for tasks requiring the temporal video boundary for certain query texts. This work introduces a novel text-video localization pre-text task to enable fine-grained temporal and semantic alignment such that the trained model can accurately perceive temporal boundaries in videos given the text description. Specifically, text-video localization consists of moment retrieval, which predicts start and end boundaries in videos given the text description, and text localization which matches the subset of texts with the video features. To produce temporal boundaries, frame features in several videos are manually merged into a long video sequence that interacts with a text sequence. With the localization task, our method connects the fine-grained frame representations with the word representations and implicitly distinguishes representations of different instances in the single modality. Notably, comprehensive experimental results show that our method significantly improves the state-of-the-art performance on various benchmarks, covering text-to-video retrieval, video question answering, video captioning, temporal action localization and temporal moment retrieval. The code will be released soon.
研究の動機と目的
- 動画フレームとテキスト記述間の微細な時間的および意味的整合を学習する動機付け。
- 局在化を監督するための時系列アノテーションを必要としない事前学習タスクを開発する。
- 局在化誘導型のマルチモーダル学習を通じて、下流の動画言語タスク全体で一般化を高める。
提案手法
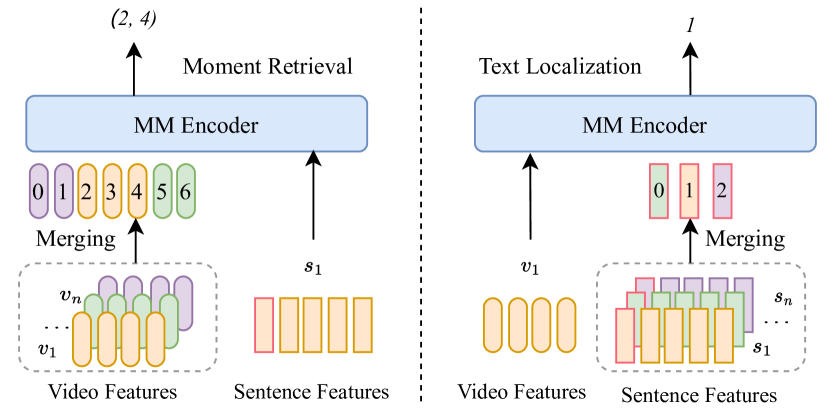
- 特徴を融合するマルチモーダルエンコーダを用いた動画用とテキスト用のデュアルエンコーダを使用する。
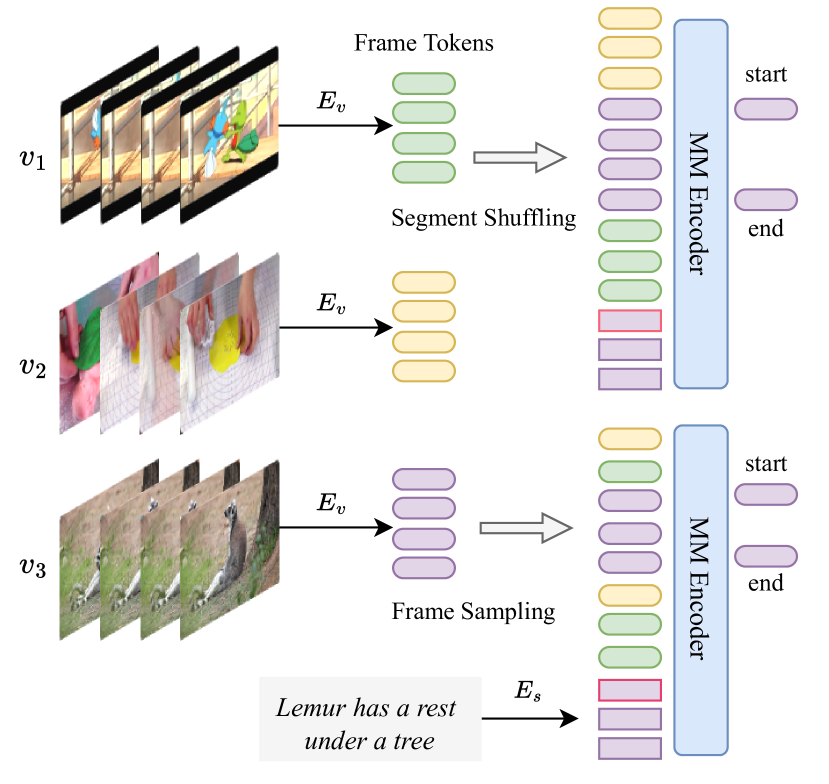
- 複数の動画からのフレーム特徴を結合して長い動画シーケンスを構築し、統合されたテキストトークンと整合させる。
- 言語を用いたモーメント検索と動画を用いたテキスト局在化の2つの局在化目的を導入する。
- マスクド言語モデリングと提案された局在化損失とともに、テキスト-動画対照学習目標を適用するとともに、併用する。
- 統合された動画フレームの開始/終了境界と、統合されたテキストトークンの対応位置を分類ベースの損失を用いて予測する。
実験結果
リサーチクエスチョン
- RQ1局在化ベースの事前学習目的は、時系列アノテーションなしで微細なフレーム-to-ワード整合を改善できるか。
- RQ2短い動画-テキストのペアを長いシーケンスに統合することで、事前学習中に効果的なモーメント局在化とテキスト局在化を実現できるか。
- RQ3検索、QA、キャプショニング、時間局在タスクにおけるゼロショットおよびファインチューニング時の性能に対するテキスト-動画局在化の影響は何か。
- RQ4動画およびテキストシーケンスの統合戦略は、局在化の品質と下流タスクの性能にどう影響するか。
主な発見
- TemPVLはMSR-VTTとDiDeMoでゼロショットのテキスト〜動画検索を改善し、MSVDとLSMDCで向上を達成する。
- この手法は強力なベースラインよりも、動画Q&Aと動画キャプショニングの性能を向上させる。
- 抽出された特徴と局在化誘導型事前学習により、時系列アクション局在化とモーメント検索が改善され、従来手法よりも向上が見られる。
- 動画統合のハードサンプリングとCLSベースのテキスト統合が局在化精度と下流タスク性能を向上させる。
- 異なるバックボーン(SwinT、ViT)とTVLを組み合わせると、タスクを跨ぐ一貫した向上を示し、堅牢な一般化を示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。