[論文レビュー] Tensor Network Quantum Simulator With Step-Dependent Parallelization
本論文では、段階に依存する並列化を備えたテンソルネットワーク量子シミュレータを提示する。これにより、1,024ノードのThetaスパコンを用いて、210キュービット、1,785ゲートを有する最大規模のQAOA回路シミュレーションを実現した。この手法は、段階に依存する変数選択に基づく新規スライシングアルゴリズムを用い、縮約幅とメモリ使用量を低減し、非並列化手法に比べ最大512倍の高速化を達成しながらも、複数のシミュレーションにわたり高い効率を維持した。
In this work, we present a new large-scale quantum circuit simulator. It is based on the tensor network contraction technique to represent quantum circuits. We propose a novel parallelization algorithm based on \stepslice . In this paper, we push the requirement on the size of a quantum computer that will be needed to demonstrate the advantage of quantum computation with Quantum Approximate Optimization Algorithm (QAOA). We computed 210 qubit QAOA circuits with 1,785 gates on 1,024 nodes of the the Cray XC 40 supercomputer Theta. To the best of our knowledge, this constitutes the largest QAOA quantum circuit simulations reported to this date.
研究の動機と目的
- 大規模な量子回路、特にQAOAの古典的シミュレーションの限界を押し広げ、量子優位性の閾値を定義すること。
- テンソルネットワーク縮約を用いた深さのある量子回路のシミュレーションにおける高いメモリおよび計算コストに対処すること。
- 縮約幅とメモリ使用量を低減するスケーラブルで高性能な並列化戦略を開発すること。
- 最適化および分析を可能にするために、複数のQAOAパrameter変動においても縮約順序を効率的に再利用できること。
提案手法
- シミュレータは量子回路をテンソルネットワークとして表現し、縮約順序生成にバケットエリミネーションアルゴリズムを用いる。
- 段階に依存する変数選択に基づく新規スライシングアルゴリズムにより、現在の縮約段階に応じてスライシング変数を動的に選択し、最大縮約幅を低減する。
- 事前に一部を縮約することで、テンソル式をより小さな部分に分割し、繰り返しのエリミネーション順序計算の必要性を最小限に抑える。
- アルゴリズムは分散システム(Thetaスパコン)に実装されており、最大1,024ノードおよび213 TBのメモリを活用している。
- 同じ縮約順序を再利用することで、複数の振幅のシミュレーションを最小限のオーバーヘッドで効率的に行える。
- スライシング戦略は、段階ごとの最大縮約幅を最小化するように最適化されており、並列インデックス数の変化に応じた性能評価が行われた。
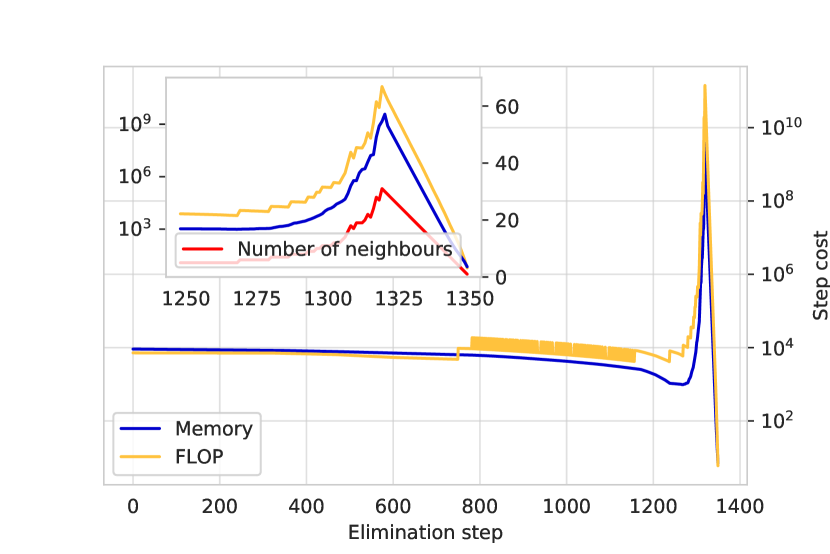
実験結果
リサーチクエスチョン
- RQ1段階に依存するスライシングは、大規模なテンソルネットワークシミュレーションにおいて、縮約幅とメモリ使用量を顕著に低減できるか?
- RQ2高度な並列化を用いたテンソルネットワーク縮約により、QAOA回路で実現可能な最大キュービット数は何か?
- RQ3段階に依存するスライシングは、標準的な並列化手法と比較して、スピードアップとメモリ効率の面でどの程度優れているか?
- RQ4異なるQAOAパrameterセット間で、1つの縮約順序をどの程度再利用可能か、シミュレーションの高速化にどの程度寄与するか?
- RQ5並列インデックス数を増加させることで、最小縮約幅および全体のシミュレーション時間にどのような影響が生じるか?
主な発見
- 本シミュレータは、1,785ゲートを有する210キュービットのQAOAアーキテクチャ状態を成功裏にシミュレートし、これまでにない最大規模のQAOA回路シミュレーション記録を樹立した。
- Thetaスパコンの1,024ノードを用いて、64ノード実行と比較して時間は3倍短縮され、縮約幅は29にまで低減された。
- 段階に依存するスライシングアルゴリズムは、非並列化された縮約ステップと比較して最大512倍の高速化を達成し、単純な並列化の理論的限界(64倍)を上回った。
- 累積メモリ使用量は、64ノードで利用可能な13 TBの60%にまで低減され、これはシリアルアプローチと比較して35倍以上も少ないメモリ使用量を意味する。
- スライスインデックス数が1つ増えるごとに、最小縮約幅が1ずつ減少し、予測可能でスケーラブルな性能向上が確認された。
- アルゴリズムにより、異なるQAOAパrameterセット間で縮約順序を効率的に再利用でき、大規模なパrameter最適化や角度の再利用可能性に関する研究を可能にした。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。