[論文レビュー] Testing the General Deductive Reasoning Capacity of Large Language Models Using OOD Examples
この論文は、規則の多様性、証明の深さ、幅、構成性を横断して、LLMの一般的な演繹推論をテストするプログラム可能な合成データセット PrOntoQA-OOD を導入し、文脈内デモンストレーションを超えた OOD generalization を評価する。
Given the intractably large size of the space of proofs, any model that is capable of general deductive reasoning must generalize to proofs of greater complexity. Recent studies have shown that large language models (LLMs) possess some abstract deductive reasoning ability given chain-of-thought prompts. However, they have primarily been tested on proofs using modus ponens or of a specific size, and from the same distribution as the in-context examples. To measure the general deductive reasoning ability of LLMs, we test on a broad set of deduction rules and measure their ability to generalize to more complex proofs from simpler demonstrations from multiple angles: depth-, width-, and compositional generalization. To facilitate systematic exploration, we construct a new synthetic and programmable reasoning dataset that enables control over deduction rules and proof complexity. Our experiments on four LLMs of various sizes and training objectives show that they are able to generalize to compositional proofs. However, they have difficulty generalizing to longer proofs, and they require explicit demonstrations to produce hypothetical subproofs, specifically in proof by cases and proof by contradiction.
研究の動機と目的
- LLMs がデモンストレーションを超えるより複雑な証明へ一般化するかを評価する。
- modus ponens を超える複数の演繹規則に対する一般化を評価する。
- 合成世界モデルから生成される証明における深さ、幅、および構成的一般化を検討する。
- 演繹課題における一般化に対する文脈内学習と監督付き学習の影響を決定する。
提案手法
- PrOntoQA-OOD を作成し、複数の演繹規則と制御可能な証明の深さと幅を備えた PrOntoQA を拡張したプログラム可能な合成データセット。
- 証明を木構造として表現し、深さ(証明連鎖の長さ)と幅(1ステップあたりの前提の数)を定量化する。
- 異なる演繹規則をサブ証明へ組み込む再帰的手続きにより、構成的な証明を生成する。
- ショートカットヒューリスティックを防ぐための誤誘導要素を含め、推論ステップの堅牢な評価を可能にする。
- CoT出力を意味論的に一階述語論理に解析して各推論ステップを検証し、有効性と前提への近さを保証する。
- in-distribution および out-of-distribution 条件下で、GPT-3.5、PaLM、LLaMA、FLAN-T5 に対する eight-shot Chain-of-Thought prompting を評価する。
実験結果
リサーチクエスチョン
- RQ1CoT デモンストレーションを提示された場合、Modus ponens を超える完全な演繹規則の集合を LLM が学習できるか。
- RQ2LLMs はデモンストレーションで見られたものより深く広い証明(深さ/幅の一般化)および構成的証明(1つの証明に複数の規則)へ一般化できるか?
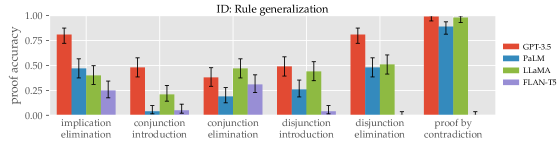
- RQ3明示的なデモンストレーションなしで、見たことのない演繹規則(OOD ルール一般化)へどの程度一般化できるか。
- RQ4文脈内学習と監督学習が一般的な演繹推論を可能にする際の比較はどうなるか。
- RQ5誤誘導要素が OOD 一般化とショートカット解法の回避に与える影響は何か。
主な発見
- LLMs は CoT プロンプティングを用いて構成的な証明へ一般化できるが、長い証明は依然として難解。
- モデルの性能はサイズと強く相関しない;指示チューニングを受けた小型モデルは大規模モデルと同程度の性能を示すことがある。
- LLMs は明示的なデモンストレーションがなくてもいくつかの演繹規則を使用できるが、いくつかの規則(例:選言の除去と背理法)は場合によってデモンストレーションが必要。
- ある状況では、テスト例とは異なる分布からの文脈内デモンストレーションが、ID デモンストレーションよりも構成的一般化を改善できる。
- 誤誘導要素はモデルによってはコピー回避ヒューリスティックを緩和できるが、規則とモデルによって効果は異なる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。