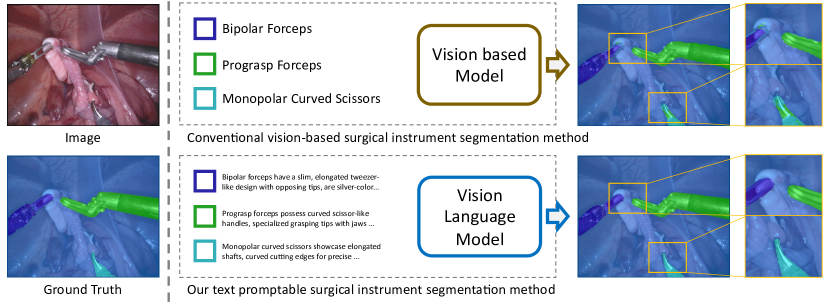
[論文レビュー] Text Promptable Surgical Instrument Segmentation with Vision-Language Models
テキストプロンプト可能な手術器具のセグメンテーションフレームワークを紹介。CLIPベースの画像・テキストエンコーダとテキストプロンプト可能なマスクデコーダ、ミックスチャー・オブ・プロンプト機構、およびハードエリア強化モジュールを組み合わせ、器具タイプ間のセグメンテーションを改善し、新カテゴリへの一般化を図る。
In this paper, we propose a novel text promptable surgical instrument segmentation approach to overcome challenges associated with diversity and differentiation of surgical instruments in minimally invasive surgeries. We redefine the task as text promptable, thereby enabling a more nuanced comprehension of surgical instruments and adaptability to new instrument types. Inspired by recent advancements in vision-language models, we leverage pretrained image and text encoders as our model backbone and design a text promptable mask decoder consisting of attention- and convolution-based prompting schemes for surgical instrument segmentation prediction. Our model leverages multiple text prompts for each surgical instrument through a new mixture of prompts mechanism, resulting in enhanced segmentation performance. Additionally, we introduce a hard instrument area reinforcement module to improve image feature comprehension and segmentation precision. Extensive experiments on several surgical instrument segmentation datasets demonstrate our model's superior performance and promising generalization capability. To our knowledge, this is the first implementation of a promptable approach to surgical instrument segmentation, offering significant potential for practical application in the field of robotic-assisted surgery. Code is available at https://github.com/franciszzj/TP-SIS.
研究の動機と目的
- 新規かつ多様な手術器具タイプへの再ラベリング・再訓練なしでの一般化の制限に対処する。
- vision-language事前学習を活用して画像領域と文本の器具プロンプトを整合させ、柔軟なオープンセットセグメンテーションを実現する。
- 注意機構と畳み込みベースのプロンプトを用いたテキストプロンプト可能なマスクデコーダを開発し、器具の局在化を段階的に refine する。
- 複数のテキストプロンプトを統合するMixture of Prompts(MoP)機構を導入し、バリアント間で堅牢なセグメンテーションを実現する。
- MAEに類似した再構成目的を組み込んだハード手術エリア強化モジュールにより、難しい領域での特徴学習を強化する。
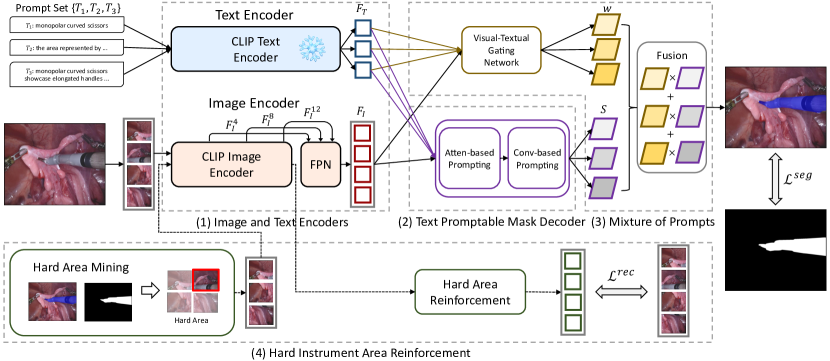
提案手法
- 内視鏡画像と器具説明の視覚・テキスト特徴を抽出するバックボーンとしてCLIP画像エンコーダとテキストエンコーダを使用する。
- 2つのプロンプト方式を備えたテキストプロンプト可能なマスクデコーダを実装する:注意ベースのプロンプティング(自己注意・クロス注意と F_T)と畳み込みベースのプロンプティング(F_Tから導出される動的カーネルパラメータ)。
- 視覚-テキストゲーティングネットワークを用いた複数プロンプトの混合(MoP)を採用し、複数のプロンプト誘導スコアマップを画素ごとに統合する。
- 難しい領域を探索するハード手術エリア強化モジュールを導入し、MAE似の再構成目的を適用して難易度の高い領域での特徴学習を強化する。
- セグメンテーション損失(二値交差エントロピー)とMAEベースモジュールの再構成損失(L2)で訓練する;テキストエンコーダを固定し、画像エンコーダをファインチューニングする。
実験結果
リサーチクエスチョン
- RQ1テキストプロンプト可能なセグメンテーションフレームワークは、再ラベリングや再訓練なしで未見の手術器具タイプへ一般化できるか。
- RQ2視覚-テキストゲーティングネットワークを介して複数のテキストプロンプトを統合すると、器具カテゴリー間のセグメンテーション精度は改善されるか。
- RQ3ハードエリア強化は、難しい手術シーンにおけるエッジの精度とカテゴリ判別を改善するか。
- RQ4マルチスケールの画像特徴融合とテキスト指示が、EndoVisデータセットのセグメンテーション性能にどう影響するか。
主な発見
| Method | Ch_IoU | ISI_IoU | BF | PF | LND | VS | GR | MCS | UP | mc_IoU |
|---|---|---|---|---|---|---|---|---|---|---|
| Ours (448) EndoVis2017 | 77.79 | 76.45 | 69.57 | 68.91 | 89.88 | 82.60 | 0.00 | 72.53 | 0.00 | 54.78 |
| Ours (896) EndoVis2017 | 79.90 | 77.83 | 68.58 | 73.52 | 92.74 | 83.90 | 0.13 | 74.70 | 0.00 | 56.22 |
| Cross-Ours (896) EndoVis2017 | 72.18 | 70.44 | 65.54 | 58.19 | 84.01 | 67.30 | 0.06 | 68.47 | 0.06 | 49.09 |
| Ours (448) EndoVis2018 | 82.67 | 81.54 | 81.53 | 70.18 | 71.54 | 90.58 | 21.46 | 65.57 | 57.51 | 65.48 |
| Ours (896) EndoVis2018 | 84.92 | 83.61 | 84.28 | 73.18 | 78.88 | 92.20 | 23.73 | 66.67 | 39.12 | 65.44 |
| Cross-Ours (896) EndoVis2018 | 66.25 | 64.92 | 65.81 | 56.12 | 44.72 | 79.77 | 1.22 | 8.97 | 4.77 | 37.34 |
- EndoVis2017およびEndoVis2018データセットで最先端の性能を達成し、伝統的な predefined-category 法や他のテキストプロンプト可能法を上回る。
- EndoVis2017で Ours (896) は Ch_IoU 79.90、ISI_IoU 77.83、mc_IoU 56.22 を達成し、複数の指標で従来法を上回る。
- EndoVis2018で Ours (896) は Ch_IoU 84.92、ISI_IoU 83.61、mc_IoU 65.44 を達成し、強いデータセット間一般化を示す。
- データセット間(EndoVis2018を訓練しEndoVis2017をテスト)でも競争力のある結果を示し、オープンセットの器具カテゴリへ一般化可能であることを示す。
- アブレーション研究は、マルチスケール特徴増強、CLSベースのテキスト特徴、注意ベースと畳み込みベースのプロンプティングの組み合わせが性能を大幅に向上させることを示す。
- MoPフレームワーク内のGPT-4生成プロンプトが、プロンプトタイプの中で最も大きな効果を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。