[論文レビュー] Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
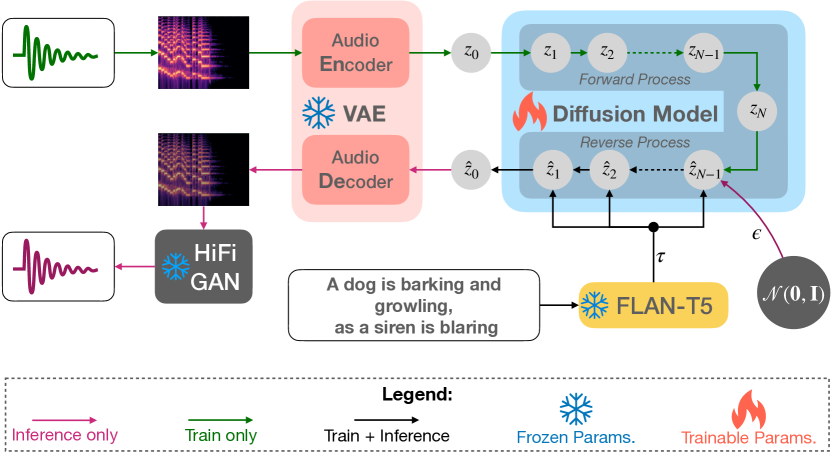
Tango はテキストエンコーダとして凍結された命令調整済み LLM(Flan-T5)を用い、潜在拡散モデルと組み合わせてテキストから音声を生成します。従来手法よりはるかに小さな学習データセットで AudioCaps において最新の結果を達成します。
The immense scale of the recent large language models (LLM) allows many interesting properties, such as, instruction- and chain-of-thought-based fine-tuning, that has significantly improved zero- and few-shot performance in many natural language processing (NLP) tasks. Inspired by such successes, we adopt such an instruction-tuned LLM Flan-T5 as the text encoder for text-to-audio (TTA) generation -- a task where the goal is to generate an audio from its textual description. The prior works on TTA either pre-trained a joint text-audio encoder or used a non-instruction-tuned model, such as, T5. Consequently, our latent diffusion model (LDM)-based approach TANGO outperforms the state-of-the-art AudioLDM on most metrics and stays comparable on the rest on AudioCaps test set, despite training the LDM on a 63 times smaller dataset and keeping the text encoder frozen. This improvement might also be attributed to the adoption of audio pressure level-based sound mixing for training set augmentation, whereas the prior methods take a random mix.
研究の動機と目的
- テキストエンコーダの微調整を最小限に抑えつつ、テキストから音声への生成を動機づける。
- 凍結したテキストエンコーダとしての指示調整済み LLM の有効性を TTA において探る。
- AudioCaps で Tango を最先端のベースラインと比較評価する。
- データセットサイズの削減とターゲットを絞ったデータ拡張によるデータ効率の高い学習を示す。
提案手法
- Flan-T5-Large を凍結したテキストエンコーダとして用い、テキスト表現を取得する。
- テキスト埋め込みを条件とした音声プライアを生成する潜在拡散モデルを採用する。
- メルスペクトログラム潜在表現から波形を再構成する音声 VAE と HiFi-GAN ボコーダーを訓練する。
- 圧力レベルに基づく音声混合データ拡張を行い、元の音源の両方をより良く保存する。
- テキストプロンプトで拡散サンプリングを操るために classifier-free ガイダンスを適用する。
- 競争力のある性能を維持しつつ、はるかに小さい AudioCaps データセット(63 倍小さい)で訓練する。
実験結果
リサーチクエスチョン
- RQ1凍結された指示調整済み LLM は、拡散ベースの音声生成器に十分なクロスモーダル指導を提供できるか?
- RQ2圧力レベルに基づくデータ拡張は TTA のクロスモーダル概念の統合を改善するか?
- RQ3AudioCaps で訓練した場合、客観的・主観的指標で Tango は AudioLDM や他のベースラインとどのように比較されるか?
- RQ4推論ステップ数とガイダンススケールが音声の品質と関連性に与える影響は何か?
主な発見
| モデル | データセット | テキスト | #Params | FD ↓ | KL ↓ | FAD ↓ | OVL ↑ | REL ↑ |
|---|---|---|---|---|---|---|---|---|
| Ground truth | - | - | - | 91.61 | 86.78 | - | - | - |
| DiffSound | AS+AC | ✓ | 400 M | 47.68 | 2.52 | 7.75 | - | - |
| AudioGen | AS+AC+8 others | ✓ | 285 M | - | 2.09 | 3.13 | - | - |
| AudioLDM-S | AC | ✗ | 181 M | 29.48 | 1.97 | 2.43 | - | - |
| AudioLDM-L | AC | ✗ | 739 M | 27.12 | 1.86 | 2.08 | - | - |
| AudioLDM-M-Full-FT | AS+AC+2 others | ✗ | 416 M | 26.12 | 1.26 | 2.57 | 79.85 | 76.84 |
| AudioLDM-L-Full | AS+AC+2 others | ✗ | 739 M | 32.46 | 1.76 | 4.18 | 78.63 | 62.69 |
| AudioLDM-L-Full-FT | AS+AC+2 others | ✗ | 739 M | 23.31 | 1.59 | 1.96 | - | - |
| Tango | AC | ✓ | 866 M | 24.52 | 1.37 | 1.59 | 85.94 | 80.36 |
- Tango は AudioCaps の監督データが AudioCaps のみで、凍結された Flan-T5 エンコーダを用い、最先端の FD (24.52)、KL (1.37)、FAD (1.59) を達成。
- Tango は主観的スコアも高く(OVL 85.94、REL 80.36)、音声品質とテキストの関連性が優れていることを示す。
- 63x 小さい訓練データセットを使用しているにもかかわらず、Tango は AudioLDM-L を上回り、いくつかの AudioLDM-FT 変種に近づくか、上回る。
- 相対的な圧力ベースの拡張は、ランダム拡張より客観指標を改善する(FD 24.52 vs 25.84; KL 1.37 vs 1.38; FAD 1.59 vs 2.72)。
- 推論ステップを増やし、適切な classifier-free ガイダンス(スケール ~3)を適用することで Tango の性能が向上し、100 から200 ステップで顕著な改善が見られる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。