[論文レビュー] Text2Motion: From Natural Language Instructions to Feasible Plans
Text2Motion は large language model planning を learned skills のライブラリと geometric feasibility planner と組み合わせて、マルチステップで長期的な操作計画を作成し検証します。挑戦的なタスクで 82% の成功率を達成し、同程度の以前の言語ベースのプランナーを 13% 上回ります。
We propose Text2Motion, a language-based planning framework enabling robots to solve sequential manipulation tasks that require long-horizon reasoning. Given a natural language instruction, our framework constructs both a task- and motion-level plan that is verified to reach inferred symbolic goals. Text2Motion uses feasibility heuristics encoded in Q-functions of a library of skills to guide task planning with Large Language Models. Whereas previous language-based planners only consider the feasibility of individual skills, Text2Motion actively resolves geometric dependencies spanning skill sequences by performing geometric feasibility planning during its search. We evaluate our method on a suite of problems that require long-horizon reasoning, interpretation of abstract goals, and handling of partial affordance perception. Our experiments show that Text2Motion can solve these challenging problems with a success rate of 82%, while prior state-of-the-art language-based planning methods only achieve 13%. Text2Motion thus provides promising generalization characteristics to semantically diverse sequential manipulation tasks with geometric dependencies between skills.
研究の動機と目的
- 自然言語の指示を feasible な symbolic および幾何学的計画へ変換する長期的なロボット計画を動機づける。
- LLM を manipulation skills のライブラリと幾何学的実現可能性プランナーと統合し、実行前に計画の実現可能性を検証する。
- 見えないタスクに対応するために shooting ベースと search ベースの計画を組み合わせたハイブリッドな計画戦略を開発する。
- 実行前に自然言語指示からゴール状態を推定する計画終了機構を提供する。
提案手法
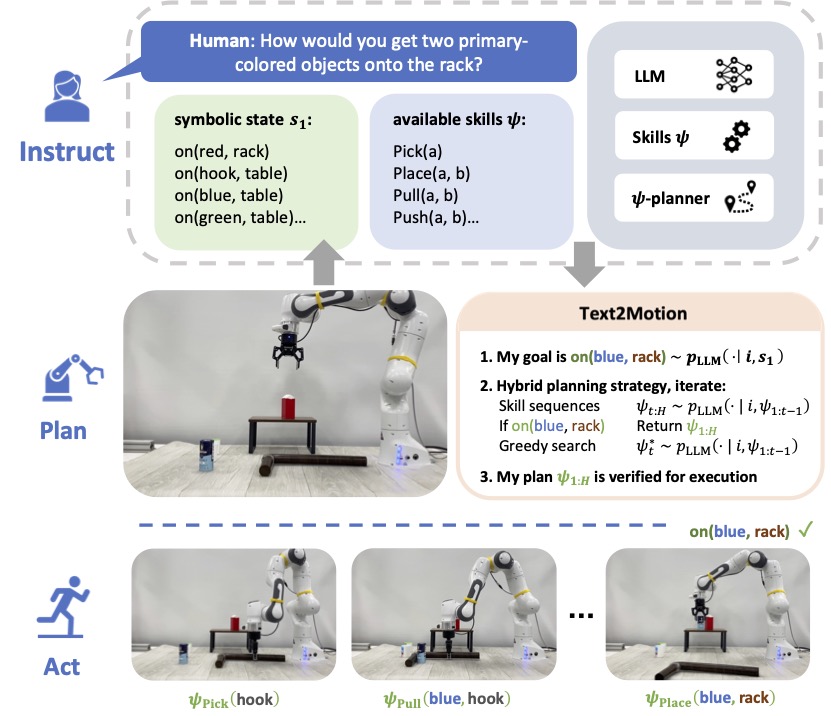
- 自然言語の指示とシーン説明から goal propositions と候補スキル列を生成するために LLM を使用する。
- 各技能をパラメータ化された manipulation primitive と、それを評価する対応する Q-function を用いた方針として表現する。
- 幾何学的実現可能性計画(STAP)を適用し、 plan に沿う各スキルの成功確率の積を最大化する(Eq. 4–5)。
- K 個の候補フルスキル列を生成し、実現可能性スコアで最適を選択する shooting ベースのプランナーを実装する(Algorithm 1)。
- LLM の有用性と幾何学的実現可能性を組み合わせて次のスキルを反復的に選択する greedy-search プランナーを実装し、可能な場合は shooting を interleave する(Eq. 8–12)。
- 実行前に幾何学的に実現可能な計画を見つけるために shooting と greedy-step 計画を交互に実行するハイブリッド Text2Motion アルゴリズムを提案する(Algorithm 3)。
- Q-value アンサンブル分散に基づくアウト・オブ・ディストリビューション検出器を組み込み、無効な OOD スキルを拒否する(Eq. 13)。
実験結果
リサーチクエスチョン
- RQ1長期的なロボット操作のために、LLM が生成した計画の正確性と実現可能性をどのように検証できるか。
- RQ2幾何学的実現可能性計画を LLM と統合することは、幾何学的依存関係を持つタスクの成功率を向上させるか。
- RQ3 shooting と探索を組み合わせたハイブリッドな計画戦略は、部分的なアフォーダンス知覚に対して、単なる近視的な言語ベースのプランナーと比べて頑健性があるか。
- RQ4事前ゴール予測は実行前の計画終了を信頼性高く提供できるか。
- RQ5 learned dynamics と Q-function を持つスキルライブラリに基づく計画の利点と制約は何か。
主な発見
- Text2Motion は長期的な卓上操作タスクの長いシーケンスに対して 82% の成功率を達成した。
- 同じ評価条件下で従来の最先端の言語ベース計画法は約 13% を達成していた。
- 複数のステップにまたがる依存関係を処理するには、スキル列全体での幾何学的実現可能性計画が不可欠である。
- shooting と greedy-search を組み合わせたハイブリッドプランナーは、幾何学的依存関係を持つタスクで、単純な近視的プランナーや純粋な計画ベースの基準よりも優れている。
- 事前ゴール予測は実行前の計画終了信号として信頼性が高い。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。