[論文レビュー] Textbooks Are All You Need
著者らは1.3Bパラメータのコードモデルphi-1を、小規模で高品質なデータセット混合(CodeTextbookとCodeExercises)を用いて訓練し、従来のモデルよりはるかに少ないデータと計算で、HumanEvalとMBPPでpass@1スコアを含む強いコード生成性能を示す。
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.
研究の動機と目的
- 高品質で教科書風のデータが、小規模なスケールでコード言語モデルの性能を劇的に向上させるかを調査する。
- 限られた訓練データと計算資源で、1.3BパラメータのTransformerが競争力のあるまたは最先端の結果を達成できることを示す。
- コーディング演習に対するターゲットを絞ったファインチューニングから生じる出現的能力と非局所的なメリットを示す。
- 合成データセットで訓練されたコードモデルの評価におけるデータキュレーション、フィルタリング、潜在的なデータ汚染の懸念を検討する。
提案手法
- CodeTextbook事前学習ミックス(The Stack/StackOverflowのコードをフィルタリングしたもの+合成教科書)を用いて、1.3Bパラメータ(24層、隠れ層サイズ2048、32ヘッド)のデコーダー専用Transformerで総トークン約50Bの訓練を行う。
- 同じハードウェアと訓練設定を用い、ハイパーパラメータを調整して、CodeExercisesデータセット(約180Mトークン)でphi-1-baseをファインチューニングしてphi-1を得る。
- HumanEvalとMBPPでpass@1を用いて、phi-1をより大きな既存モデルと比較し、phi-1-baseおよびphi-1-smallに対する出現能力を分析する。
- データフィルタリング(GPT-4による注釈とトランスフォーマー系分類器)を組み合わせて高品質な教育用コードサンプルを作成し、事前訓練とファインチューニングのためにGPT-3.5で教科書と演習を合成する。
- GPT-4で採点された型にはまらない問題セットとデータ剪定実验を用いて、性能の堅牢性を評価しデータ汚染の懸念を評価する。
- アーキテクチャ、訓練設定(fp16、AdamW、線形ウォームアップ-デケイ、8×A100、Deepspeed)、データセット構成(CodeTextbook、CodeExercises)を報告する。
実験結果
リサーチクエスチョン
- RQ1高品質で教科書のようなデータは、強力なコード生成性能を達成するために大規模な訓練データと計算資源を削減できるのか?
- RQ2小規模で焦点を絞ったデータセット(CodeExercises)でのファインチューニングが、ファインチューニング集合を超えるコードタスクに与える影響(出現的能力)とは?
- RQ3データキュレーションと合成データ生成戦略は、LLMにプログラミング概念を教える際に従来のコードコーパスより有意に優れるか?
- RQ4報告された結果は、訓練と評価ベンチマーク間の潜在的なデータ汚染やリークに対してどれだけ堅牢か?
- RQ5HumanEvalとMBPPにおけるphi-1とより大きなベースラインの比較上の強みと制限は何か?
主な発見
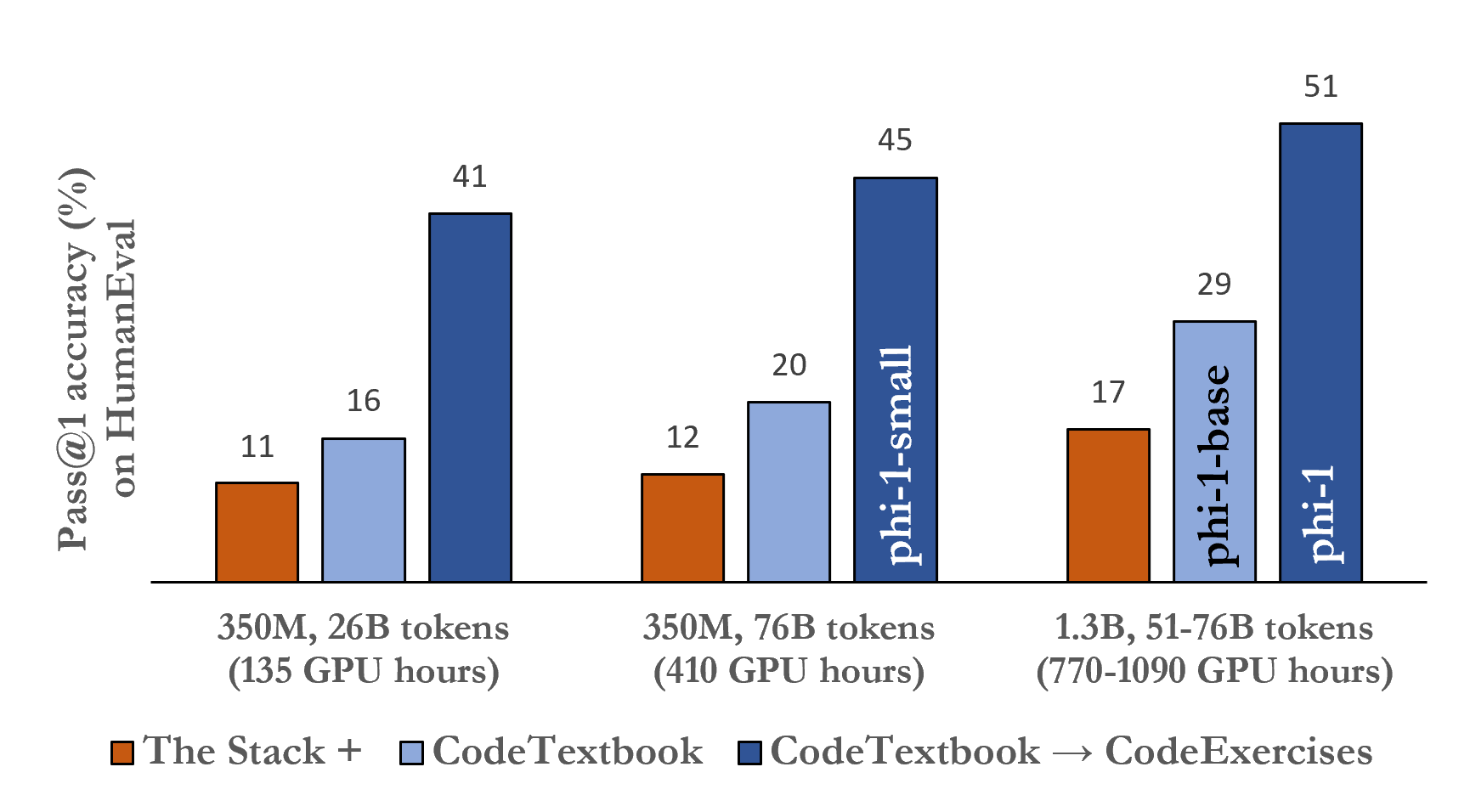
| モデル | サイズ(パラメータ) | 訓練トークン | HumanEval Pass@1 | MBPP Pass@1 |
|---|---|---|---|---|
| phi-1 | 1.3B | 7B | 50.6% | 55.5% |
| phi-1-base | 1.3B | 7B | 29% | - |
| phi-1-small | 350M | 7B | 45% | - |
- phi-1(1.3Bパラメータ)はCodeExercisesでファインチューニングした後、HumanEvalで50.6%、MBPPで55.5%のpass@1を達成。
- ファインチューニングなしでは、CodeTextbookで訓練したphi-1-baseは29%のHumanEval、phi-1-small(350M)は同じパイプラインで約45%のHumanEvalを達成。
- Phi-1は、訓練データと計算資源が桁違いに少ないにもかかわらず、HumanEvalとMBPPで多くの大規模モデルを上回るが、GPT-4は場合によっては上限となる。
- CodeExercisesでのファインチューニングは大幅な性能向上と、他のコーディングタスクやライブラリの利用(例:Pygameや Tkinter のような外部ライブラリ)で予期せぬ改善をもたらす。
- データ品質に焦点を当てた事前訓練(CodeTextbook)とターゲットを絞ったファインチューニング(CodeExercises)は、小規模で強力な結果を達成することで従来のスケーリング法則を崩す可能性がある。
- GPT-4による採点とデータ剪定実験による非定型評価は、phi-1の性能の堅牢性を支持し、データ汚染の懸念を緩和する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。