[論文レビュー] The generalization error of max-margin linear classifiers: Benign overfitting and high dimensional asymptotics in the overparametrized regime
この論文は、過パラメータ化設定における max-margin 線形分類器の一般化誤差の正確な高次元漸近を導出し、良性な過適合の条件を特定し、ランダム特徴モデルを分析する。
Modern machine learning classifiers often exhibit vanishing classification error on the training set. They achieve this by learning nonlinear representations of the inputs that maps the data into linearly separable classes. Motivated by these phenomena, we revisit high-dimensional maximum margin classification for linearly separable data. We consider a stylized setting in which data $(y_i,{\boldsymbol x}_i)$, $i\le n$ are i.i.d. with ${\boldsymbol x}_i\sim\mathsf{N}({\boldsymbol 0},{\boldsymbol Σ})$ a $p$-dimensional Gaussian feature vector, and $y_i \in\{+1,-1\}$ a label whose distribution depends on a linear combination of the covariates $\langle {\boldsymbol θ}_*,{\boldsymbol x}_i \rangle$. While the Gaussian model might appear extremely simplistic, universality arguments can be used to show that the results derived in this setting also apply to the output of certain nonlinear featurization maps. We consider the proportional asymptotics $n,p\to\infty$ with $p/n\to ψ$, and derive exact expressions for the limiting generalization error. We use this theory to derive two results of independent interest: $(i)$ Sufficient conditions on $({\boldsymbol Σ},{\boldsymbol θ}_*)$ for `benign overfitting' that parallel previously derived conditions in the case of linear regression; $(ii)$ An asymptotically exact expression for the generalization error when max-margin classification is used in conjunction with feature vectors produced by random one-layer neural networks.
研究の動機と目的
- トレーニング誤差が0に近づく高次元・過パラメータ化領域における max-margin分類器の研究を動機づける。
- ガウス特徴モデルの下で、これらの分類器がいつ良く一般化するか(benign overfitting)を特徴付ける。
- 一般化誤差と補間閾値の明示的な漸近式を提供する。
- 結果をランダム特徴量モデルおよび広いニューラル/ネットワークに触発された特徴化へ拡張する。
- 共分散構造と信号整列(シグナルアライメント)に関する一般化挙動を支配する条件を提供する。
提案手法
- 独立同分布データを仮定し、特徴 x_i ~ N(0, Σ) およびラベル y_i が f(⟨θ*, x_i⟩) によって分布する。
- n, p → ∞ かつ p/n → ψ となる比例漸近を採用する。
- ガウス等価モデルと普遍性の議論を通じて max-margin分類器の極限一般化誤差 Err*(μ, ψ) を導出する。
- 正のマージンが可能になる補間閾値 ψ*(μ) を特徴付ける。
- 特徴が単一のランダム隠れ層の出力であるランダム特徴モデルを解析し、普遍性を適用して正確な漸近を得る。
- Gordon のガウス比較フレームワークを用いて問題をほぼ分離可能な凸-凹形へ還元し、非線形方程式系を抽出する。
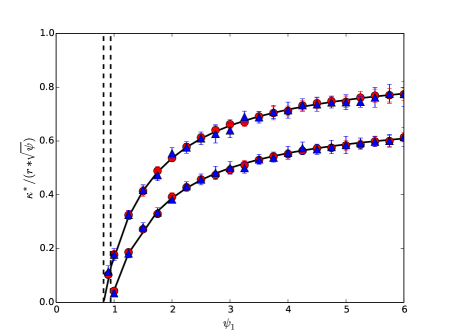
実験結果
リサーチクエスチョン
- RQ1ガウス特徴の下で、ハイディメンショナルで過パラメータ化設定の max-margin 線形分類器の極限一般化誤差は何か?
- RQ2Σと θ* に対する良性過適合を生む十分必要条件は何か?
- RQ3補間閾値(正のマージンが得られる最小の p/n)はデータ共分散と信号構造にどう依存するか?
- RQ4漸近結果はランダム特徴量モデルや広義のニューラルネットワーク領域へ拡張されるか?
- RQ5ガウス等価アプローチはリッジ回帰を超えるマージンと誤差の正確な予測をもたらすか?
主な発見
- マージンと予測誤差は n → ∞ において、確率的に非ランダムな極限 κ*(μ, ψ) および Err*(μ, ψ) に収束する。
- Σと θ* の特定のスペクトルおよびアライメント条件の下で良性過適合が発生し、線形回帰で知られている結果と一致する。
- studied high-dimensional regime で max-margin classifier がほぼ Bayes 誤差を達成するには過パラメータ化(大きな ψ)が必要。
- ランダム特徴モデルでは、幅 p の増加に伴いテスト誤差が低下し、large overparametrization limit p/n ≫ 1 で最小となる。
- 解析は excess error が小さいときのバイアス様項 B_n(λ) および分散様項 V_n(λ) を明示的に提供し、適切なパラメータ選択に対して ε-整合性結果を与える。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。