[論文レビュー] The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models
Hallucinations Leaderboard を導入する、トレーニングなしで複数のタスクに渡る事実性と忠実度を評価する LLM を対象とするオープンプラットフォーム。幻覚傾向を定量化する。モデルファミリー、指示チューニング、サイズ効果を分析する。
Large Language Models (LLMs) have transformed the Natural Language Processing (NLP) landscape with their remarkable ability to understand and generate human-like text. However, these models are prone to ``hallucinations'' -- outputs that do not align with factual reality or the input context. This paper introduces the Hallucinations Leaderboard, an open initiative to quantitatively measure and compare the tendency of each model to produce hallucinations. The leaderboard uses a comprehensive set of benchmarks focusing on different aspects of hallucinations, such as factuality and faithfulness, across various tasks, including question-answering, summarisation, and reading comprehension. Our analysis provides insights into the performance of different models, guiding researchers and practitioners in choosing the most reliable models for their applications.
研究の動機と目的
- 多様なタスクと設定において LLM が幻覚を生み出す頻度を定量化する。
- 幻覚を事実性と忠実度のカテゴリーに区別する。
- モデルファミリー、サイズ、指示による微調整(instruction fine-tuning)の幻覚傾向に及ぼす影響を評価する。
提案手法
- ゼロショットおよび少数ショット評価のために EleutherAI Evaluation Harness を採用する。
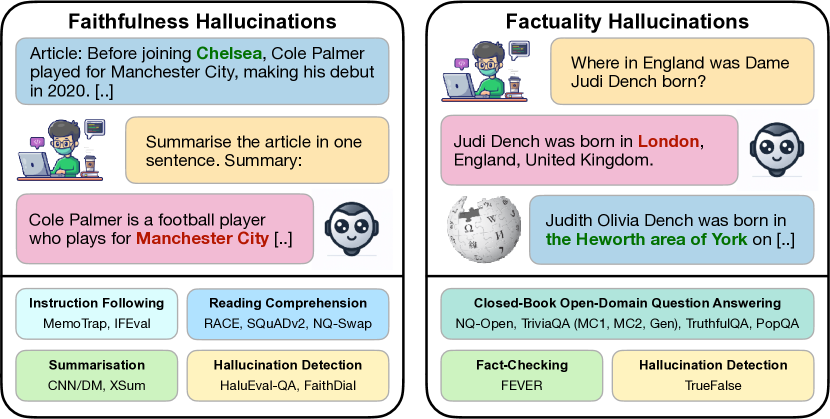
- タスク横断で二つの幻覚の範囲(事実性と忠実度)を定義する。
- タスク指標を平均して二つの総合スコア(事実性スコアと忠実度スコア)を用いる。
- 複数のモデルファミリーとサイズにわたって、オープンソースのバックボーンと微調整版を評価する。
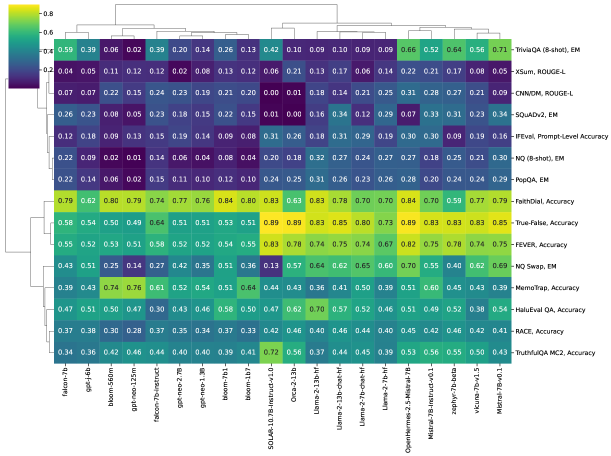
- ヒートマップと階層的クラスタリングを用いて、モデルとタスク間のパターンを特定する。
実験結果
リサーチクエスチョン
- RQ1異なる LLM ファミリーは、タスク横断で事実性と忠実度を比較するとどうなるか?
- RQ2指示微調整(instruction fine-tuning)が幻覚傾向に与える影響は何か?
- RQ3モデルサイズは事実性と忠実度にどのように影響するか?
- RQ4指示に従うことと事実的正確さの間にトレードオフはあるか?
- RQ5本研究の知見は、幻覚におけるモデルの priors および memory に関する先行研究と一致するか?
主な発見
- 指示チューニングを施したモデルは一般に忠実度を向上させるが、事実性には混在または限定的な向上しか示さない。
- 事実性はサイズの増大からより大きな恩恵を受ける傾向があり、忠実度ほどではない。
- モデルクラスタリングは個々のアーキテクチャよりもモデルファミリーに沿う傾向があり、共有された訓練データの影響を示唆する。
- GPT-Neo および Llama-2 系列は、QA、要約、検出タスクで異なる強みを示す。
- 記憶ベースのタスク(例: NQ-open)は、根底にある真実表現にもかかわらず、表層的な事実性が弱いことを示す。
- The Hallucinations Leaderboard は、指示に従うこと(忠実度)と事実的に正確な内容を生成すること(事実性)との既存のトレードオフを浮き彫りにする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。