[論文レビュー] The Impact of Positional Encoding on Length Generalization in Transformers
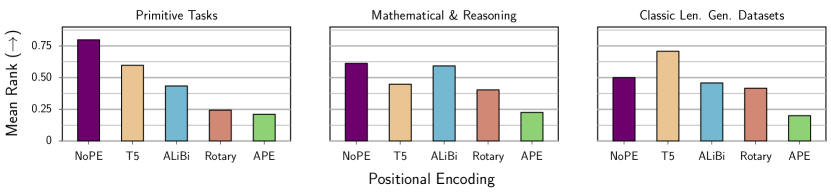
NoPE(ポジショナルエンコーディングなし)は、デコーダー専用トランスフォーマーの長さ一般化において、推論および数学タスク全般で明示的な位置エンコーディングを上回る。NoPE は絶対位置と相対位置の両方を表現でき、しばしば T5 の Relative PE のように振る舞う。
Length generalization, the ability to generalize from small training context sizes to larger ones, is a critical challenge in the development of Transformer-based language models. Positional encoding (PE) has been identified as a major factor influencing length generalization, but the exact impact of different PE schemes on extrapolation in downstream tasks remains unclear. In this paper, we conduct a systematic empirical study comparing the length generalization performance of decoder-only Transformers with five different position encoding approaches including Absolute Position Embedding (APE), T5's Relative PE, ALiBi, and Rotary, in addition to Transformers without positional encoding (NoPE). Our evaluation encompasses a battery of reasoning and mathematical tasks. Our findings reveal that the most commonly used positional encoding methods, such as ALiBi, Rotary, and APE, are not well suited for length generalization in downstream tasks. More importantly, NoPE outperforms other explicit positional encoding methods while requiring no additional computation. We theoretically demonstrate that NoPE can represent both absolute and relative PEs, but when trained with SGD, it mostly resembles T5's relative PE attention patterns. Finally, we find that scratchpad is not always helpful to solve length generalization and its format highly impacts the model's performance. Overall, our work suggests that explicit position embeddings are not essential for decoder-only Transformers to generalize well to longer sequences.
研究の動機と目的
- ゼロから訓練したデコーダーのみのトランスフォーマーにおいて、異なる位置エンコーディング方式が長さ一般化にどのように影響するかを調査する。
- Absolute Position Embedding (APE)、T5 の Relative PE、ALiBi、Rotary、NoPE を、推論と数学タスクの一連の課題で比較する。
- 下流タスクにおいて、NoPE が長さ一般化を支援・上回ることができるかを評価する。
提案手法
- 自動回帰目的で訓練された約107Mパラメータの従来型デコーダーのみのトランスフォーマーをゼロから訓練する。
- 5つの位置エンコーディング方式を評価する:APE(正弦波)、T5 の Relative Bias、ALiBi、Rotary、NoPE(PEなし)。
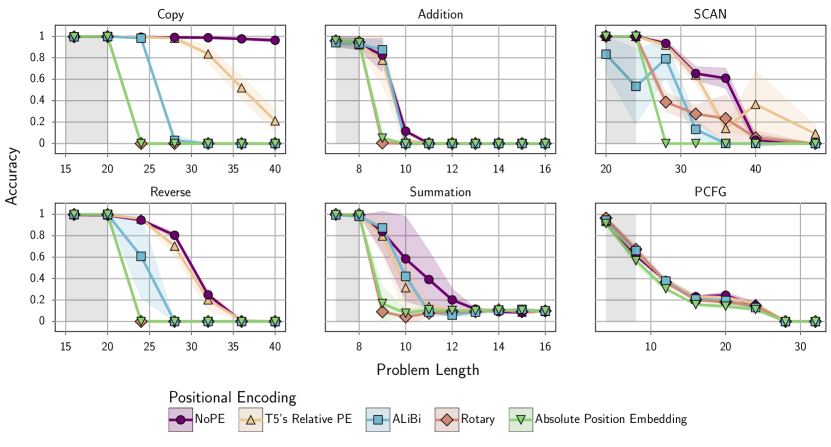
- Primitive (Copy、Reverse) などの合成タスクと、Addition、Polynomial Eval.、Sorting、Summation、Parity、LEGO の数学・推論タスク、および古典的データセット(SCAN、PCFG)を含むタスクリストでの性能を評価する。
- 長さ一般化を、長さ up to L(デフォルトは L=20)で訓練し、長さ up to 2L で評価する。IISD/拡張長のシナリオを含む。
- 注意分布(アテンションパターン)と scratchpad(Chain-of-Thought)形式を分析し、PEと長さ一般化の相互作用を理解する。
- NoPE が絶対位置エンコーディングと相対位置エンコーディングの両方を表現できることを理論的に示し、 SGD が NoPE を訓練して T5 の RPE に類似した相対エンコーディングの振る舞いを取るという実証的証拠を提供する。
実験結果
リサーチクエスチョン
- RQ1NoPE を導入しないこと(NoPE)で、デコーダーのみのトランスフォーマーの長さ一般化は、多様な下流タスクで改善されるのか。
- RQ2APE、T5 Relative Bias、ALiBi、Rotary、NoPE のうち、長いシーケンスへの外挿で最も優れた PE スキームはどれか。
- RQ3NoPE は組み込み的に絶対位置と相対位置の両方を表現できるのか、ゼロから訓練した場合には実務上どちらに近い振る舞いを示すのか。
- RQ4Scratchpad(CoT)フォーマットは、長さ一般化において各 PE とどのように相互作用するのか。
- RQ5各 PE が引き起こすアテンションパターンの違いは何で、それが長さ一般化の性能とどう関連するのか。
主な発見
- NoPE は、複数のタスクで長さ一般化において明示的な位置エンコーディング(APE、ALiBi、Rotary、さらには T5 の Relative Bias)を一貫して上回る。
- NoPE は、追加の計算を要さずに一般化を達成でき、明示的な PE が追加の項を必要とするアテンションとは異なる。
- 理論的な結果は NoPE が絶対位置エンコーディングと相対位置エンコーディングの両方を表現できることを示すが、SGD で訓練された NoPE の挙動は T5 の RPE に類似した相対 PE アテンションパターンと一致する。
- Scratchpad は、長さ一般化を改善するのは一部のタスクに限られ、フォーマットと使用する PE に依存する。
- アテンション分析は、NoPE と T5 の Relative PE が長長期・短長期の両方の位置を参照する傾向を促進する一方、ALiBi は最近のトークンに偏り、Rotary は APE に類似した振る舞いを示すことを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。