[論文レビュー] The Landscape and Challenges of HPC Research and LLMs
この論文は、大規模言語モデル(LLMs)を高性能計算(HPC)に適応させる方法を概説し、課題と道筋、コード表現、マルチモーダルアプローチ、潜在的なケーススタディについて議論します。
Recently, language models (LMs), especially large language models (LLMs), have revolutionized the field of deep learning. Both encoder-decoder models and prompt-based techniques have shown immense potential for natural language processing and code-based tasks. Over the past several years, many research labs and institutions have invested heavily in high-performance computing, approaching or breaching exascale performance levels. In this paper, we posit that adapting and utilizing such language model-based techniques for tasks in high-performance computing (HPC) would be very beneficial. This study presents our reasoning behind the aforementioned position and highlights how existing ideas can be improved and adapted for HPC tasks.
研究の動機と目的
- LLMsとHPCの間の相互利益の可能性を強調することで、HPCタスクへのLLMsの適用を動機づける。
- データ表現、ツールアクセス、評価指標など、HPCへのLLMsの導入におけるドメイン特有の課題を特定する。
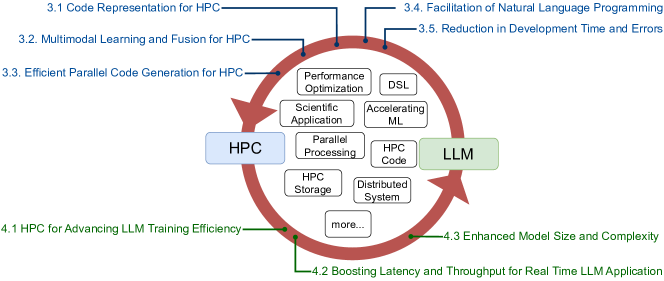
- コード表現、マルチモーダル学習、並列コード生成を含む、HPC対応のLLMのためのアーキテクチャ的・方法論的方向性を提案する。
- ケーススタディを通じて、特定用途に合わせた設計がLLMsとHPCの相互利益を可能にする方法を示す。
提案手法
- プログラミングおよびHPCの文脈におけるLLMsに関する既研究をレビューしてギャップを特定する。
- HPC向けのコード表現(ソーステキストとLLVM IRを含む)と、それらがLLMタスクに与える影響について論じる。
- コード特徴とシステム実行時データを統合するマルチモーダル学習を探索し、性能最適化を目指す。
- LLMsによる並列コード生成を分析し、データ入手性や評価指標などの課題を概説する。
- HPC志向の自然言語プログラミングにおけるNL-to-PLおよびPL-to-NLの側面を説明する。
- 最新のHPC特化コードLLMsと、ドメインに特化することで学習要件を削減できる点を要約する。
実験結果
リサーチクエスチョン
- RQ1HPCタスクへLLMsを適用する際の主要な機会は何か、そしてHPCとLLM研究の間にどのような相互利益が生じるか?
- RQ2データ表現、ツール、評価など、LLMsを効果的に活用するために対処すべきHPC特有の課題は何か?
- RQ3コード表現(例:LLVM IR)とマルチモーダル融合はHPCにおけるLLMの有効性をどう向上させるか?
- RQ4HPC向けに特化したコードLLMsの現状はどうか、並列コード生成と最適化タスクにおけるギャップは何か?
主な発見
- LLMsは並列コード生成などのHPCタスクを支援する可能性があるが、課題には並列構成全体での堅牢性と正確性が含まれる。
- LLVM IRのようなコード表現はHPCにとって重要な意味特徴を露出でき、特定のタスクでは生のソーステキスト表現よりも優れている場合がある。
- コード特徴とパフォーマンスカウンタやシステム情報を組み合わせたマルチモーダルアプローチは、HPC最適化タスクを向上させる可能性がある。
- 最先端のHPC向けLLM(例:Code LLMsとHPC調整モデル)は有望だが、並列コードのデータ入手性と評価指標によって制約を受ける。
- HPC向けにNL-to-PLおよびPL-to-NLのパラダイムが提案され、使いやすさと理解を向上させるために双方の方向でHPC特有の知識を強調する。
- LLMの訓練とデータ前処理のためにHPCリソースを統合した将来のパイプラインは、効率とスケーラビリティを向上させる可能性がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。