[論文レビュー] The Natural Language Decathlon: Multitask Learning as Question Answering
この論文は decaNLP(十のタスクを質問応答として再定義したマルチタスクベンチマーク)と、MQAN(複数タスクQAモデル)を紹介します。MQAN は複数のタスクを横断して優れた性能を発揮するマルチポインター-ジェネレータデコーダを備え、転移とゼロショットの能力を可能にします。
Deep learning has improved performance on many natural language processing (NLP) tasks individually. However, general NLP models cannot emerge within a paradigm that focuses on the particularities of a single metric, dataset, and task. We introduce the Natural Language Decathlon (decaNLP), a challenge that spans ten tasks: question answering, machine translation, summarization, natural language inference, sentiment analysis, semantic role labeling, zero-shot relation extraction, goal-oriented dialogue, semantic parsing, and commonsense pronoun resolution. We cast all tasks as question answering over a context. Furthermore, we present a new Multitask Question Answering Network (MQAN) jointly learns all tasks in decaNLP without any task-specific modules or parameters in the multitask setting. MQAN shows improvements in transfer learning for machine translation and named entity recognition, domain adaptation for sentiment analysis and natural language inference, and zero-shot capabilities for text classification. We demonstrate that the MQAN's multi-pointer-generator decoder is key to this success and performance further improves with an anti-curriculum training strategy. Though designed for decaNLP, MQAN also achieves state of the art results on the WikiSQL semantic parsing task in the single-task setting. We also release code for procuring and processing data, training and evaluating models, and reproducing all experiments for decaNLP.
研究の動機と目的
- 統一されたマルチタスクベンチマーク(decaNLP)を提案するため、十の多様なNLPタスクを文脈を介した質問応答として位置づける。
- タスク特化モジュールを持たない単一のマルチタスクQAネットワークMQANを開発し、全てのdecaNLPタスクを共同学習させる。
- decaNLPでのマルチタスク学習に起因する転移学習、ドメイン適応、およびゼロショット能力を実証する。
- 抗カリキュラム訓練がマルチタスク性能をさらに向上させ、MQANが意味解析の単一タスクにおいても強力な結果を達成することを示す。
提案手法
- 文脈・質問・回答の三つ組みで、QA問題として十のNLPタスクを再設定する(QA、翻訳、要約、NLI、感情分析、SRL、関係抽出、対話、意味解析、代名詞解決)。
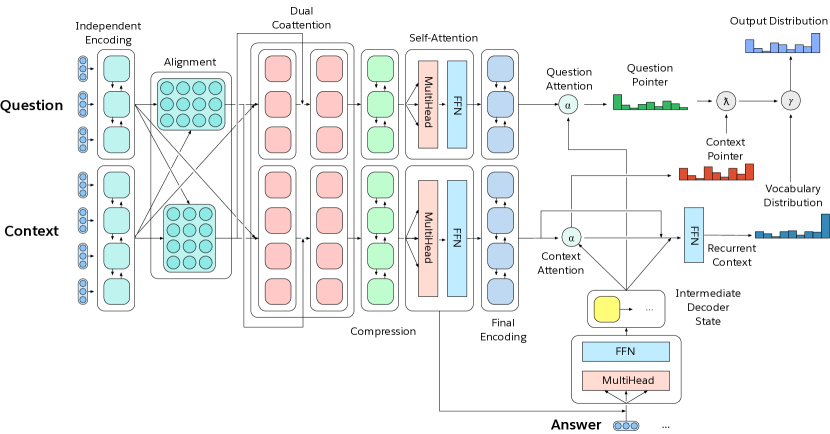
- 双方向共注意エンコーダを備え、文脈と質問を同時に注意付けし、外部語彙から生成したり、文脈からコピーしたり、質問からコピーすることができる多重ポインター-ジェネレータデコーダを持つMQANを提案する。
- anti-curriculum戦略とともにすべてのdecaNLPタスクでMQANを訓練し、そのゼロショットおよび転移能力を分析する。
- タスク固有の指標をdecaScore(各タスク0-100)に対応付けて評価し、十タスクを横断して集計する。
- 再現性とリーダーボード追跡のために、オープンソースのコードとデータ処理パイプラインを提供する。
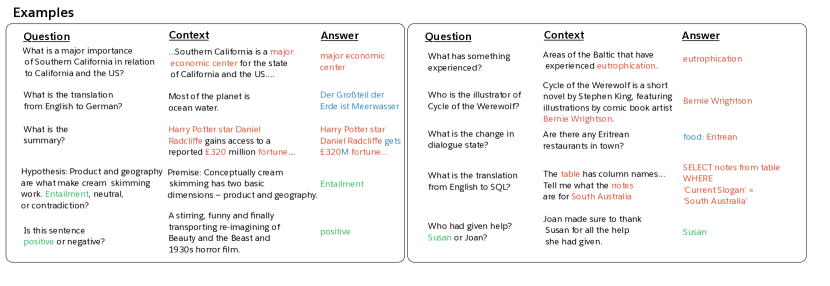
実験結果
リサーチクエスチョン
- RQ1十の多様なNLPタスクをQAとしてフレーム化した単一モデルが、タスク特化モジュールなしで全タスクにおいて競争力のある性能を発揮できるか。
- RQ2decaNLPでのマルチタスク学習は、トレーニング分布を超えた新しいドメイン、言語、関連タスクへの転移学習の利点をもたらすか。
- RQ3コピー、生成、質問ベースの曖昧性解決を要するタスクで、マルチポインター-ジェネレータデコーダがどのように性能に寄与するか。
- RQ4カリキュラム訓練と抗カリキュラム訓練戦略が、decaNLPの性能と安定性にどのような影響を与えるか。
主な発見
- MQAN は decaNLP の複数タスクにおいて、マルチタスク設定と単一タスク設定の両方で競争力のある性能を達成する。
- マルチポインター-ジェネレータデコーダは、文脈および質問からの効果的なコピーと、外部語彙からの生成を可能にし、出力ニーズが異なるタスクにとって重要である。
- 抗カリキュラム訓練は、完全に結合訓練だけを行う場合よりも、decaNLP の性能を向上させる。
- decaNLP で事前学習した MQAN は、機械翻訳および固有表現認識における転移利益、感情分析および自然言語推論のドメイン適応、テキスト分類のゼロショット能力を示す。
- MQAN は単一タスク設定の WikiSQL の意味解析で最先端の結果を達成する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。