[論文レビュー] The Recent Advances in Automatic Term Extraction: A survey
tldr: 監督付き用語抽出の総合調査。ニューラルおよびTransformerベースのモデルを中心に、古典的な特徴量設計アプローチと比較し、データセット・指標・課題を議論。
Automatic term extraction (ATE) is a Natural Language Processing (NLP) task that eases the effort of manually identifying terms from domain-specific corpora by providing a list of candidate terms. As units of knowledge in a specific field of expertise, extracted terms are not only beneficial for several terminographical tasks, but also support and improve several complex downstream tasks, e.g., information retrieval, machine translation, topic detection, and sentiment analysis. ATE systems, along with annotated datasets, have been studied and developed widely for decades, but recently we observed a surge in novel neural systems for the task at hand. Despite a large amount of new research on ATE, systematic survey studies covering novel neural approaches are lacking. We present a comprehensive survey of deep learning-based approaches to ATE, with a focus on Transformer-based neural models. The study also offers a comparison between these systems and previous ATE approaches, which were based on feature engineering and non-neural supervised learning algorithms.
研究の動機と目的
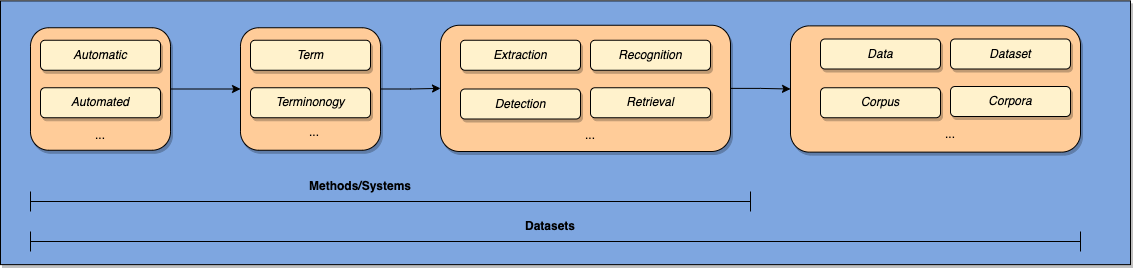
- 過去30年間の用語抽出に関するリソースと公開コーパスを調査する。
- Transformerベースのモデルを中心に、従来の特徴量設計アプローチと対比させつつ、深層学習ベースのATE手法を系統的にレビューする。
- ATEの評価指標を分類し、直接評価と間接評価の方法論を分析する。
- 多語・ネスト型用語抽出と堅牢性の課題を特定し、今後の研究方向を提案する。
提案手法
- ATEリソースを、公的に入手可能なモノリンガルおよびマルチリンガルのコーパスを調査して識別・分類する。
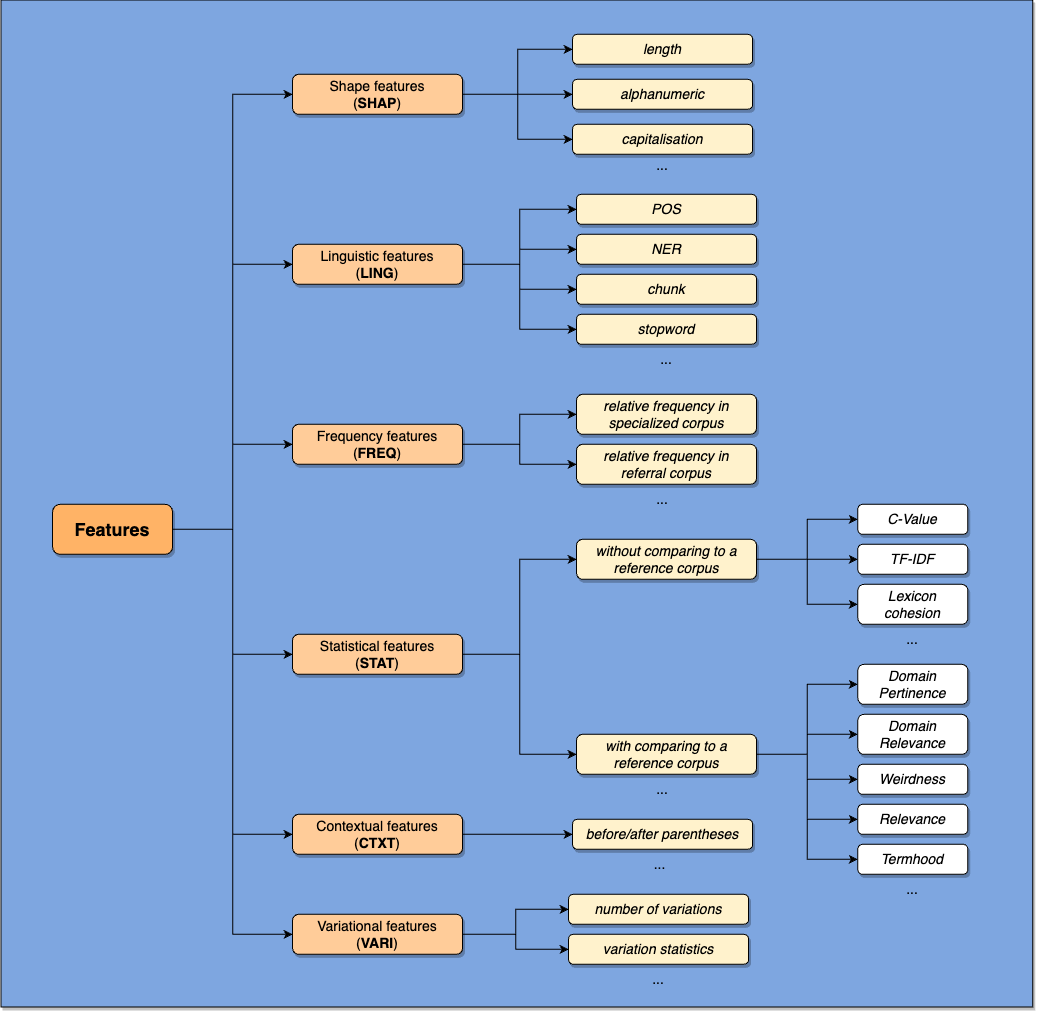
- 従来の特徴工学アプローチとニューラルアプローチを対比させつつ、監督付きATEシステムを系統的にレビューする。
- ATEに用いられる埋め込み表現(一般的、ドメイン特化、文脈依存)と、それらが性能に与える影響を論じる。
- AINを含むニューラルアーキテクチャ(系列/分類モデル、系列対系列モデル)を説明し、転移学習パラダイム内での位置付けを示す。
- 既存データセットとシステムからの洞察を基に、評価実践を要約し、今後の方向性を提案する。
実験結果
リサーチクエスチョン
- RQ1モノリンガルおよびマルチリンガルATEの公開データセットとコーパスは何で、時間とともにどのように発展してきたか?
- RQ2Transformerベースおよびその他のニューラルATEシステムは、性能と堅牢性の点で伝統的な特徴工学法とどう比較されるか?
- RQ3ATEで主に用いられる評価指標と方法論は何で、それらは下流タスクとどう関連するか?
- RQ4多語・ネスト型用語抽出などATEの主な残課題は何で、それを今後どう解決できるか?
主な発見
- ニューラルおよびTransformerベースのアプローチはATEでより一般的になり、手作業で設計された特徴に依存する伝統的手法を上回ることが多い。
- 一般知識とドメイン特性を組み合わせた埋め込み戦略、および文脈埋め込みはATEの性能を向上させる。
- ACTERのような注釈付きマルチリンガルコーパスは、跨言語・跨ドメインATEの強力なベンチマークを提供し、より堅牢な比較を可能にする。
- モノリンガルコーパスの注釈スキームと評価プロトコルには大きなばらつきがあり、データセット間の比較を困難にしている。
- 評価実践には直接評価(ゴールドスタンダード、人間判断)と間接評価(下流タスク)を含むが、標準化されたベンチマークの必要性がある。
- 現在の課題として、複数語・ネスト型用語の正確な把握と、言語・ドメインを横断したシステムの堅牢性の向上が挙げられる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。