[論文レビュー] The Semantic Scholar Open Data Platform
この論文は Semantic Scholar Open Data Platform と Semantic Scholar Academic Graph (S2AG) を説明し、データ処理パイプライン、意味的機能、公開API/データセットを概説します。
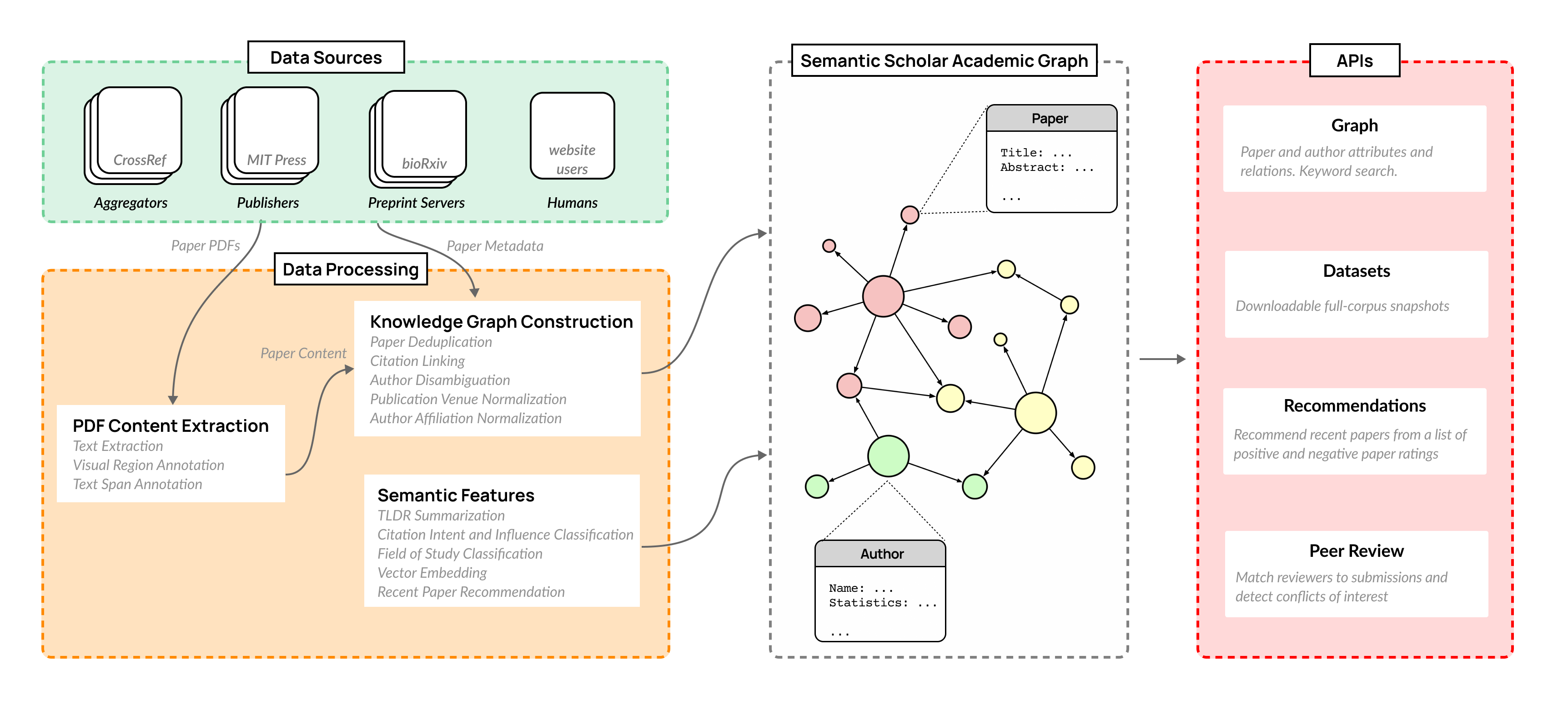
The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
研究の動機と目的
- 情報過多を管理するための自動化された学術データツールの必要性を喚起する。
- Semantic Scholar Open Data Platform および S2 Academic Graph (S2AG) を大規模で曖昧さのない知識グラフとして説明する。
- 学術コンテンツを抽出し構造化するためのデータ処理パイプライン、データソース、および手法を説明する。
- S2AG と意味的特徴へアクセスを提供する公開APIとダウンロード可能なデータセットの詳細を述べる。
- 意味 labeling の強化、パーソナライズ、協働ベースの注釈の促進に向けた今後の方向性を概説する。
提案手法
- 50 以上のソースからメタデータとPDFを取り込み、曖昧さのない知識グラフ(S2AG)を構築する。
- PDFコンテンツ抽出を実行し、構造化テキスト、セクション、図、表、参考文献を取得する。
- 視覚領域注釈とテキストスパン注釈を用いて、抽出された内容をレイアウトと意味ラベルで豊かにする。
- 重複排除(S2APLER)、著者の曖昧さ排除(S2AND)、所属正規化(S2AFF)を適用して一意のエンティティを構築する。
- TLDR 要約、引用意図/影響、研究分野分類、論文埋め込み(SPECTER)、および推奨などの意味機能を生成する。
- API および月次データセットスナップショット(論文、著者、引用、埋め込み、TLDR、会場、S2ORC)をプログラムによるアクセスに提供する。
実験結果
リサーチクエスチョン
- RQ1多様なデータソースから、規模の大きい、オープンで、かつ曖昧さのない学術グラフ(S2AG)をどのように構築できるか?
- RQ2要約、埋め込み、分類など、科学文献の発見と理解を高めるためにどのような意味機能を追加できるか?
- RQ3研究者は API とデータセットを介して、包括的な学術データと意味注釈へプログラム的にアクセス・ダウンロードできるか?
- RQ4継続的な出版物と訂正に追随するために、知識グラフを最新に保つにはどのような構成要素とパイプラインが必要か?
主な発見
- S2AG は、205M 論文、80M 著者、550k 会場、580M 論文-著者エッジ、2.4B 引用エッジ(記述されたパイプライン時点)と近似される大規模な学術グラフである。
- プラットフォームは、構造的に解析されたテキスト、TLDR 要約、ベクトル埋め込み(SPECTER)、推奨などの高度な意味機能を提供する。
- パイプラインは 50 を超えるデータソース、洗練された PDF コンテンツ抽出(Text Explanation、Visual Region Annotation、Text Span Annotation)、および複数の正規化/曖昧さ排除モデル(S2APLER、S2AND、S2AFF)を統合している。
- 公開 API と月次データセットが提供され、コアメタデータ、要約、全文(ライセンスがある場合)、引用、埋め込み、TLDR へアクセスできる。
- システムは、意味処理のための多様なモデルとデータセットを提供しており、TLDR (CatTS)、引用意図のための SciCite、研究分野のための S2FOS、SPECTER 埋め込み、動的な推奨などを含む。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。