[論文レビュー] The Step Decay Schedule: A Near Optimal, Geometrically Decaying Learning Rate Procedure For Least Squares
この論文は、SGD の最終反復が多項式で減衰するステップサイズではストリーミング最小二乗法に対して最適ではなく、幾何的減衰スケジュールを導入することで minimax レートにほぼ到達し、既知ホライズン設定で対数因子まで最適性に近いことを示す。
Minimax optimal convergence rates for classes of stochastic convex optimization problems are well characterized, where the majority of results utilize iterate averaged stochastic gradient descent (SGD) with polynomially decaying step sizes. In contrast, SGD's final iterate behavior has received much less attention despite their widespread use in practice. Motivated by this observation, this work provides a detailed study of the following question: what rate is achievable using the final iterate of SGD for the streaming least squares regression problem with and without strong convexity? First, this work shows that even if the time horizon T (i.e. the number of iterations SGD is run for) is known in advance, SGD's final iterate behavior with any polynomially decaying learning rate scheme is highly sub-optimal compared to the minimax rate (by a condition number factor in the strongly convex case and a factor of $\sqrt{T}$ in the non-strongly convex case). In contrast, this paper shows that Step Decay schedules, which cut the learning rate by a constant factor every constant number of epochs (i.e., the learning rate decays geometrically) offers significant improvements over any polynomially decaying step sizes. In particular, the final iterate behavior with a step decay schedule is off the minimax rate by only $log$ factors (in the condition number for strongly convex case, and in T for the non-strongly convex case). Finally, in stark contrast to the known horizon case, this paper shows that the anytime (i.e. the limiting) behavior of SGD's final iterate is poor (in that it queries iterates with highly sub-optimal function value infinitely often, i.e. in a limsup sense) irrespective of the stepsizes employed. These results demonstrate the subtlety in establishing optimal learning rate schemes (for the final iterate) for stochastic gradient procedures in fixed time horizon settings.
研究の動機と目的
- Streaming 最小二乗法における SGD の最終反復の挙動を、強凸性の有無に関係なく特徴づける。
- 最終反復に対する多項式的減衰ステップサイズのサブ最適性を示す。
- 幾何的減衰ステップデケイ Schedule を提案・分析し、 minimax レートに近づくことを示す。
- 既知ホライゾンの結果と SGD の anytime(極限)挙動を対比する。
- synthetic least squares と CIFAR-10 の residual network の両方で経験的検証を提供する。
- ホライゾンの知識の下でのハイパーパラメータ調整の実務的影響を議論する。
提案手法
- 最小二乗法の下での確率的勾配オラクルを用いる SGD を形式化し、ノイズと4次モーメント共分散の仮定を設定する。
- ステップサイズを定義する:多項式減衰 eta_t ~ a/(b+t^alpha) およびステップデケイ(幾何的)スケジュール(アルゴリズム 1)。
- 強凸性あり/なしの場合の最終反復のサブ最適性を示す下界を導出する。
- ステップデケイが minimax レートに近い上界を与えることを示し、過剰リスクの境界が log(T)因子だけ異なることを示す。
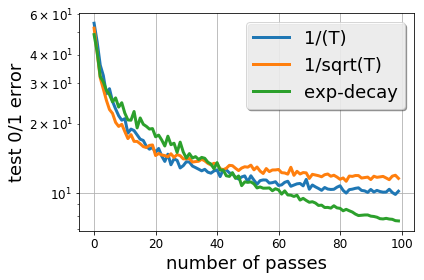
- CIFAR-10 の ResNet-44 を用いた実験を通じて、減衰スキームを比較し suffix 平均化の効果を議論する。
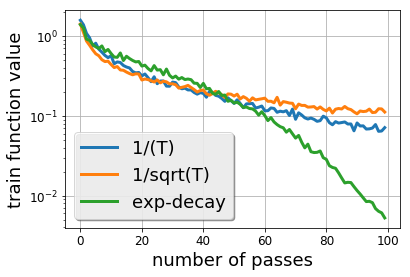
実験結果
リサーチクエスチョン
- RQ1SGD の最終反復は固定ホライゾン T の下で minimax レートに匹敵し得るか?
- RQ2多項式的減衰ステップサイズはステップデケイスケジュールと比較して最終反復性能をサブ最適にするのか?
- RQ3強凸/非強凸の least squares において、ステップデケイスケジュールは minimax レートにどれだけ近づくのか?
- RQ4SGD の最終反復の known-horizon と anytime の挙動の違いは何か?
- RQ5実世界のネットワーク上の経験的結果は、ステップデケイスケジュールの理論的利点を裏付けるか?
主な発見
- 多項式的減衰ステップサイズは最終反復のレートをサブ最適にし、条件数(強凸)でのギャップ、または sqrt(T)/log T(非強凸)のギャップが生じる。
- ステップデケイスケジュールは minimax レートに近づき、既知ホライゾンの下で最終反復の過剰リスクは log(T) 因子のみ異なる。
- 強凸の場合、下界は多項値の減衰を持つ任意の最終反復が κ 因子のサブ最適性を負うことを示し、滑らかな場合は √T/log T のギャップを示す。
- 実装には初期学習率と終了時刻 T のみが必要であり、強凸の場合は log 因子を log(kappa) に減らす refinements が可能。
- anytime(極限)挙動は、ステップサイズスキームに依らず依然として低下がなく minimax レートから離れた limsup を取る。
- CIFAR-10 の ResNet-44 における実証結果は、連続的なステップデケイ(指数関数的減衰)が多項式減衰を上回ることが多く、suffix 平均化は非凸設定で一般化を害する可能性がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。