[論文レビュー] The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning
要約: 論文は整合性調整は大部分表面的である可能性を示唆し、基盤LLMがほとんどの知識をエンコードしていることを示し、最小プロンプトでSFT/RLHFに整合したモデルと同等かそれ以上を達成できるチューニング不要のインコンテキスト整合手法 Urial を提案する。
The alignment tuning process of large language models (LLMs) typically involves instruction learning through supervised fine-tuning (SFT) and preference tuning via reinforcement learning from human feedback (RLHF). A recent study, LIMA (Zhou et al. 2023), shows that using merely 1K examples for SFT can achieve significant alignment performance as well, suggesting that the effect of alignment tuning might be "superficial." This raises questions about how exactly the alignment tuning transforms a base LLM. We analyze the effect of alignment tuning by examining the token distribution shift between base LLMs and their aligned counterpart. Our findings reveal that base LLMs and their alignment-tuned versions perform nearly identically in decoding on the majority of token positions. Most distribution shifts occur with stylistic tokens. These direct evidence strongly supports the Superficial Alignment Hypothesis suggested by LIMA. Based on these findings, we rethink the alignment of LLMs by posing the research question: how effectively can we align base LLMs without SFT or RLHF? To address this, we introduce a simple, tuning-free alignment method, URIAL. URIAL achieves effective alignment purely through in-context learning (ICL) with base LLMs, requiring as few as three constant stylistic examples and a system prompt. We conduct a fine-grained and interpretable evaluation on a diverse set of examples, named JUST-EVAL-INSTRUCT. Results demonstrate that base LLMs with URIAL can match or even surpass the performance of LLMs aligned with SFT or SFT+RLHF. We show that the gap between tuning-free and tuning-based alignment methods can be significantly reduced through strategic prompting and ICL. Our findings on the superficial nature of alignment tuning and results with URIAL suggest that deeper analysis and theoretical understanding of alignment is crucial to future LLM research.
研究の動機と目的
- 整合性調整(SFTおよびRLHF)がベースLLMの挙動をどう変えるかを、ベースモデルと整合モデル間のトークン分布のシフトを分析して調べる。
- インコンテキスト学習と prompting を用いてチューニングなしでもベースLLMを効果的に整合できるかを評価する。
- Urial を提案・評価する:チューニング不要の整合手法で、再スタイリングされたインコンテキストデモとシステムプロンプトに依拠する。
- 多様なタスクで整合手法を比較する、解釈可能な多面的評価プロトコルを提供する。
提案手法
- ベースLLMと整合型の対訳を比較して、整合性調整で何が変化するのかをトークン分布のシフトから理解する。
- Urial を開発:3つの固定スタイル例とシステムプロンプトを用いたインコンテキスト学習のチューニング不要な整合手法。
- just-eval-instruct データセット(9件のソースからの1,000指示)を作成・使用して出力品質の六つの側面を評価する。
- GPT-4 および ChatGPT による人間検証付きで六つの評価テンプレートを実装・評価する。
- Urial を SFT、RLHF、ベース ICL、検索拡張 ICL に対して複数のベースモデルで比較する。
- 知識保持と安全挙動について定量的スコアと定性的観察の両方を報告する。
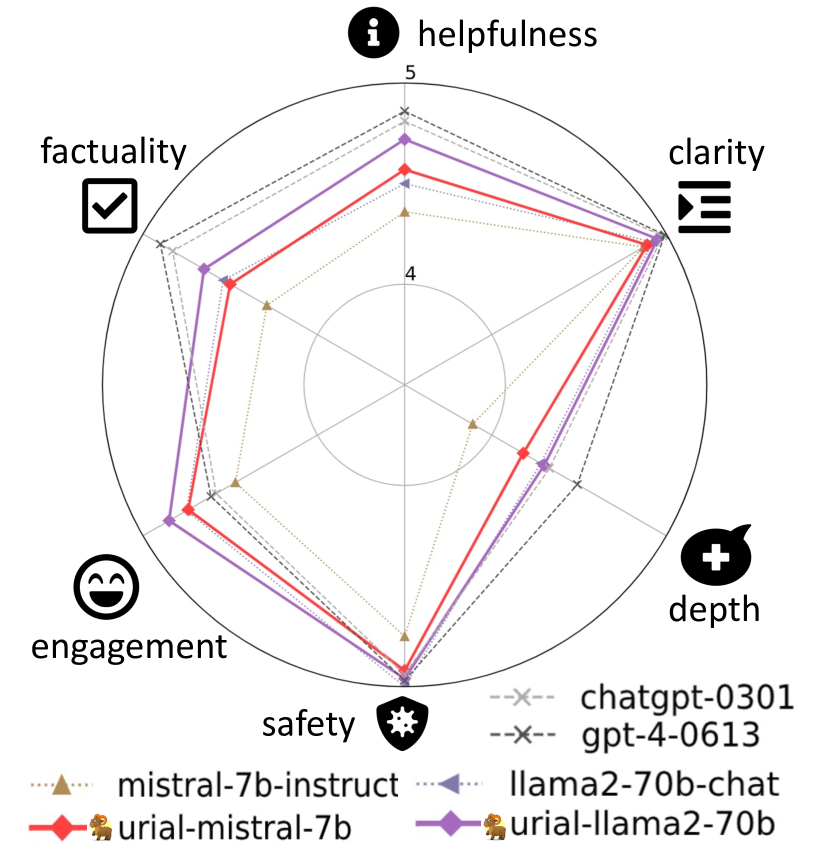
実験結果
リサーチクエスチョン
- RQ1整合性調整は主に知識内容ではなく、スタイル的トークンを変化させるだけなのか?
- RQ2インコンテキスト学習と prompting によってチューニングなしでベースLLMを効果的に整合できるのか?
- RQ3Urial はモデルやタスクの多様性において従来のチューニングベースの整合手法とどのように比較されるのか?
主な発見
- 整合性調整はトークンのごく一部の割合に影響を与えるだけで、知識関連の内容の大部分はベースLLMと共有される。
- スタイル的および安全性に関連するトークンが整合中に最大の分布シフトを示す。
- 頻度が高く安定した3つのインコンテキスト例とシステムプロンプトだけで、Urial は強力な基盤LLM に対してSFT/RLHFと同等以上を達成できる。
- Urial はいくつかの設定で Mistral-7b-Instruct および Llama-2-70b-chat-q を上回ることができ、整合ベースの手法との差を縮める。
- より細かい多面的評価は総合スコアを超えたニュアンスのある比較を支える。
- K=3 のような適度なインコンテキスト例の数で、安全性や他の側面を調整でき、強いバランスを提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。