[論文レビュー] Tight Auditing of Differentially Private Machine Learning
この論文は、自然データセット上で DP-SGD の厳密な監査スキームを導入し、f-DP/GDP を活用して機構固有の尾部推定を用いることで、2回の学習実行のみでほぼ理論的なプライバシー保証を得る方法を示す。また、このアプローチが private ML コードの実装バグを検出する方法も示している。
Auditing mechanisms for differential privacy use probabilistic means to empirically estimate the privacy level of an algorithm. For private machine learning, existing auditing mechanisms are tight: the empirical privacy estimate (nearly) matches the algorithm's provable privacy guarantee. But these auditing techniques suffer from two limitations. First, they only give tight estimates under implausible worst-case assumptions (e.g., a fully adversarial dataset). Second, they require thousands or millions of training runs to produce non-trivial statistical estimates of the privacy leakage. This work addresses both issues. We design an improved auditing scheme that yields tight privacy estimates for natural (not adversarially crafted) datasets -- if the adversary can see all model updates during training. Prior auditing works rely on the same assumption, which is permitted under the standard differential privacy threat model. This threat model is also applicable, e.g., in federated learning settings. Moreover, our auditing scheme requires only two training runs (instead of thousands) to produce tight privacy estimates, by adapting recent advances in tight composition theorems for differential privacy. We demonstrate the utility of our improved auditing schemes by surfacing implementation bugs in private machine learning code that eluded prior auditing techniques.
研究の動機と目的
- 最悪ケース監査を超える、より厳密で実用的な経験的プライバシー推定の必要性を動機づける。
- DP-SGD の下で自然データセットに対して厳密なプライバシー推定を得られる監査スキームを開発する。
- 数千回の訓練から、少数で実行可能な回数へ、監査の計算負担を削減する。
- DP-SGD 実装を直接検査できるようにして、プライバシー関連のバグを検出できるようにする。
提案手法
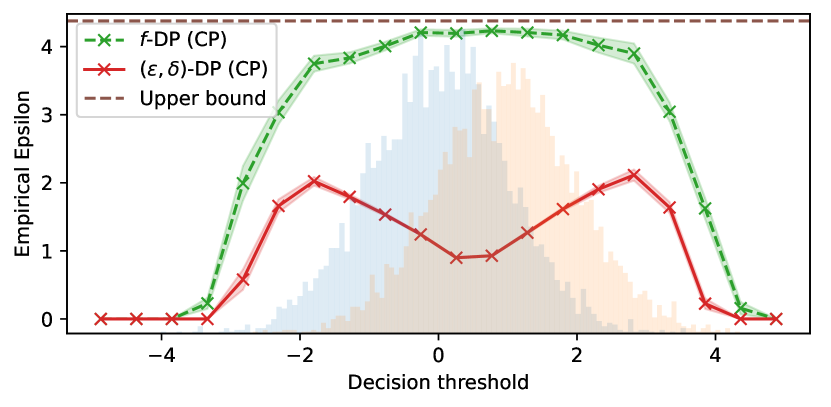
- 機構の真のプライバシー・トレードオフを捉えるように、監査を f-DP/GDP 設定で位置づける。
- PLD(privacy loss distribution)と Gaussian DP を適用して、プライバシーパラメータの厳密な下限を得る。
- 観測された偽陽性/偽陰性率からプライバシーパラメータを境界付けるために Clopper-Pearson 法とベイズ技術を用いる。
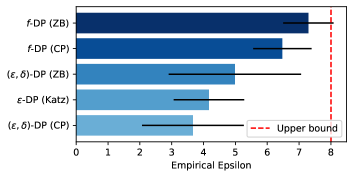
- GDP ベースの監査を標準的な (epsilon, delta)-DP 監査と比較し、より少ない観測でより厳密な境界を示す。
- 白箱からブラックボックスまでの脅威モデルを検討し、現実的な攻撃者能力下での監査の有効性を評価する。
実験結果
リサーチクエスチョン
- RQ1DP-SGD の実証的なプライバシー漏えいを、最悪ケースだけでなく自然データセット上でも厳密に推定できるか?
- RQ2DP-SGD の厳密な経験的プライバシー境界を得るには、何回の訓練実行が必要か?
- RQ3f-DP/GDP による特定のプライバシ機構に合わせた監査は、汎化的な DP 監査アプローチより優れているか?
- RQ4監査はこれまでの方法では見逃されていた DP-SGD 実装のバグを暴露できるか?
- RQ5異なる攻撃者の脅威モデルは、プライバシー監査の厳密さと実用性にどのように影響するか?
主な発見
- GDP を用いた監査は、従来の epsilon-delta 監査よりも実証的なプライバシー境界をはるかに厳密にし、はるかに少ない観測で理論値に近い値を達成する。
- 提案されたスキームは、自然データセット上の DP-SGD に対して厳密なプライバシー推定を得るのに、わずか2回の訓練実行で足りる。
- Gaussian/functional DP フレームワークに監査を合わせ、PLD を用いることで、組み合わせとサブサンプリング下での DP-SGD のプライバシー損失の正確な境界を得られる。
- 監査は、従来の監査手法に見逃されていた DP-SGD の実装バグを暴露できる。
- 脅威モデルを意識した監査(白箱設定やブラックボックス設定を含む)は、更新またはデータへのアクセスが実証的プライバシー推定の厳密さに与える影響を示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。