[論文レビュー] TIM: Teaching Large Language Models to Translate with Comparison
TIMは出力と好みの比較を用いた翻訳のファインチューニングにより、翻訳品質、ゼロショット性能、モデルサイズを超えた堅牢性を改善する。
Open-sourced large language models (LLMs) have demonstrated remarkable efficacy in various tasks with instruction tuning. However, these models can sometimes struggle with tasks that require more specialized knowledge such as translation. One possible reason for such deficiency is that instruction tuning aims to generate fluent and coherent text that continues from a given instruction without being constrained by any task-specific requirements. Moreover, it can be more challenging for tuning smaller LLMs with lower-quality training data. To address this issue, we propose a novel framework using examples in comparison to teach LLMs to learn translation. Our approach involves presenting the model with examples of correct and incorrect translations and using a preference loss to guide the model's learning. We evaluate our method on WMT2022 test sets and show that it outperforms existing methods. Our findings offer a new perspective on fine-tuning LLMs for translation tasks and provide a promising solution for generating high-quality translations. Please refer to Github for more details: https://github.com/lemon0830/TIM.
研究の動機と目的
- 標準的な指示チューニングを超えるオープンソースLLMの翻訳改善を動機づける。
- 新規の比較機構を通じて高品質な翻訳データの小規模セットを活用する。
- 出力と好みの比較信号を導入して翻訳学習を正規化・誘導する。
- TIMがモデルサイズに応じてどのようにスケールし、ゼロショット翻訳へ一般化するかを評価する。
- 翻訳品質に影響を与える推論戦略とデータタイプについて洞察を提供する。
提案手法
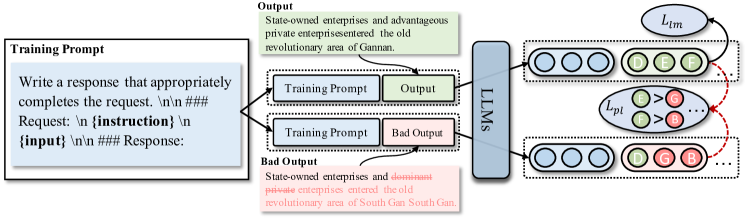
- 同じ入力に対して異なる指示へ対応する出力を学習するための出力比較を導入する。
- より良い翻訳を悪い翻訳と区別する好み比較損失を導入する。
- 出力を正則化するトークンレベルの好み損失 L_pl を追加する(論文に式が示される)。
- L_plと標準言語モデリング損失を組み合わせる(L = L_lm + λ L_pl、λ = 1.0)。
- 比較のための3種類データを構築する:order-guided(順序ガイド)、dictionary-guided(辞書ガイド)、error-guided(誤りガイド)データ。
- パラメータ効率と性能を評価するために3つのチューニング戦略(LoRA、FixEmb、Full)を検討する。
- WMT22とFLORES-200をEN ⇄ DEおよび ZH ⇄ ENで評価し、複数のバックボーンモデル(例:BLOOMZ-7b-mt、LLaMA-2-7b/13b)で評価する。

実験結果
リサーチクエスチョン
- RQ1比較ベースのファインチューニングはオープンソースLLMにおける翻訳品質を標準的な指示チューニングと比べて改善できるか?
- RQ2出力比較と好み比較は翻訳における幻覚の低減と信頼性の向上にどのように寄与するか?
- RQ3データタイプ(順序ガイド、辞書ガイド、誤りガイド)が翻訳品質と堅牢性に与える影響は何か?
- RQ4TIMの性能はモデルサイズと語方向、ゼロショット設定を含めてどのようにスケールするか?
- RQ5TIMチューンモデルは標準的なMTベースラインや多言語MTモデルと比較して競争力があるか、あるいは優れているか?
主な発見
- TIMとその派生は、WMT22およびFLORES-200で4つの翻訳方向において、Alpaca-*, MT-*, WMT22受賞者などのいくつかのベースラインを一貫して上回る。
- TIM-LLaMA-13bは参照なしで英語↔ドイツ語翻訳においてトップ1の品質推定性能を達成。
- TIMの改善は小型モデルで特に顕著であり、比較信号と組み合わせると効率が高い。
- TIMのゼロショット多言語翻訳能力は他のいくつかのオープンソースモデルと比較して強力で、多くの方向でNLLB-3.3Bとのギャップを縮め、特にJa→Enで顕著。
- アブレーション研究は、辞書ガイドデータ、出力比較、およびLMベースの悪出力バリアントが有意な信号を提供する一方、ランダムノイズはあまり効果的でないことを示す。
- MT指標の評価は、TIM-LLaMA-13bおよびTIM-BLOOMZ-7bが参照なし指標をMQMスコア(システムレベルの精度とピアソン相関)と相関させる点で優れることを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。