[論文レビュー] TinyBERT: Distilling BERT for Natural Language Understanding
TinyBERT は、革新的な Transformer 蒸留手法と二段階学習フレームワークを用いて、BERT をより小さく高速なモデルに圧縮し、GLUE で競争力のある性能を達成します。
Language model pre-training, such as BERT, has significantly improved the performances of many natural language processing tasks. However, pre-trained language models are usually computationally expensive, so it is difficult to efficiently execute them on resource-restricted devices. To accelerate inference and reduce model size while maintaining accuracy, we first propose a novel Transformer distillation method that is specially designed for knowledge distillation (KD) of the Transformer-based models. By leveraging this new KD method, the plenty of knowledge encoded in a large teacher BERT can be effectively transferred to a small student Tiny-BERT. Then, we introduce a new two-stage learning framework for TinyBERT, which performs Transformer distillation at both the pretraining and task-specific learning stages. This framework ensures that TinyBERT can capture he general-domain as well as the task-specific knowledge in BERT. TinyBERT with 4 layers is empirically effective and achieves more than 96.8% the performance of its teacher BERTBASE on GLUE benchmark, while being 7.5x smaller and 9.4x faster on inference. TinyBERT with 4 layers is also significantly better than 4-layer state-of-the-art baselines on BERT distillation, with only about 28% parameters and about 31% inference time of them. Moreover, TinyBERT with 6 layers performs on-par with its teacher BERTBASE.
研究の動機と目的
- エッジデバイス上での事前学習済み言語モデルの計算オーバーヘッドを削減するモチベーションを示しつつ、精度を維持する。
- 教師モデルBERTの知識をより小さな学生モデルへ転送するためのTransformer特化の知識蒸留法を導入する。
- 一般領域知識とタスク固有知識を捉えるための二段階学習フレームワーク(一般蒸留とタスク固有蒸留)を提案する。
- TinyBERT がGLUEで競争力のある性能を維持しつつ、著しい速度向上とパラメータ削減を達成することを実証する。
提案手法
- Embedding層蒸留、アテンションベース蒸留、隠れ状態蒸留の3つの要素からなるTransformer蒸留損失を提案し、予測層蒸留を加える。
- 蒸留のために学生と教師の層を整合させる層マッピング関数 g(m) を使用する。
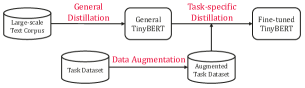
- 2段階で訓練する。まずファインチューニング前のBERTを教師として大規模一般コーパス上で一般蒸留を行い、次にファインチューニング済みBERTを教師としてデータ拡張を用いたタスク固有蒸留を行う。
- タスク固有蒸留では、BERTの予測とGloVeの類似度を組み合わせてトレーニングデータを拡張するデータ拡張を行う。
- GLUEベンチマークで、TinyBERT(4層および6層)を従来のKDベースラインおよび教師としてBERT BASEと比較して評価する。
実験結果
リサーチクエスチョン
- RQ1Transformer特化の知識蒸留は、BERTからより小さな学生へ知識を効果的に転送できるか。
- RQ2二段階蒸留フレームワーク(一般蒸留とタスク固有蒸留)は、単一段階のアプローチよりTinyBERTの性能を向上させるか。
- RQ3埋め込み層、アテンション、隠れ状態レベルの蒸留は最終性能にどう寄与するか。
- RQ4BERTをTinyBERTに圧縮する際のパラメータ数、FLOPs、推論速度のトレードオフは何か。
- RQ54層または6層のTinyBERTはGLUEタスクでBERT BASEにどれだけ近づけるか。
主な発見
| システム | #パラメータ | #FLOPs | スピードアップ | MNLI-(m/mm) | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BERT BASE (Teacher) | 109M | 22.5B | 1.0x | 83.9/83.4 | 71.1 | 90.9 | 93.4 | 52.8 | 85.2 | 87.5 | 67.0 | 79.5 |
| BERT TINY | 14.5M | 1.2B | 9.4x | 75.4/74.9 | 66.5 | 84.8 | 87.6 | 19.5 | 77.1 | 83.2 | 62.6 | 70.2 |
| BERT SMALL | 29.2M | 3.4B | 5.7x | 77.6/77.0 | 68.1 | 86.4 | 89.7 | 27.8 | 77.0 | 83.4 | 61.8 | 72.1 |
| BERT 4-PKD | 52.2M | 7.6B | 3.0x | 79.9/79.3 | 70.2 | 85.1 | 89.4 | 24.8 | 79.8 | 82.6 | 62.3 | 72.6 |
| DistilBERT 4 | 52.2M | 7.6B | 3.0x | 78.9/78.0 | 68.5 | 85.2 | 91.4 | 32.8 | 76.1 | 82.4 | 54.1 | 71.9 |
| MobileBERT TINY | 15.1M | 3.1B | - | 81.5/81.6 | 68.9 | 89.5 | 91.7 | 46.7 | 80.1 | 87.9 | 65.1 | 77.0 |
| TinyBERT 4 (ours) | 14.5M | 1.2B | 9.4x | 82.5/81.8 | 71.3 | 87.7 | 92.6 | 44.1 | 80.4 | 86.4 | 66.6 | 77.0 |
| BERT 6-PKD | 67.0M | 11.3B | 2.0x | 81.5/81.0 | 70.7 | 89.0 | 92.0 | - | - | 85.0 | 65.5 | - |
| PD | 67.0M | 11.3B | 2.0x | 82.8/82.2 | 70.4 | 88.9 | 91.8 | - | - | 86.8 | 65.3 | - |
| DistilBERT 6 | 67.0M | 11.3B | 2.0x | 82.6/81.3 | 70.1 | 88.9 | 92.5 | 49.0 | 81.3 | 86.9 | 58.4 | 76.8 |
| TinyBERT 6 (ours) | 67.0M | 11.3B | 2.0x | 84.6/83.2 | 71.6 | 90.4 | 93.1 | 51.1 | 83.7 | 87.3 | 70.0 | 79.4 |
- TinyBERT 4 は GLUE で BERT BASE の性能の 96.8% 超を達成しつつ、約7.5倍小さく、推論時約9.4倍高速。
- TinyBERT 6 は GLUE で BERT BASE の性能と同等。
- TinyBERT 4 は 4層KDベースライン(BERT-PKD、DistilBERT 4)を平均で少なくとも4.4%上回る。
- TinyBERT 4 は、BERT BASEのパラメータ約13.3%、推論時間約10.6%しかないにもかかわらず、強力な結果を達成。
- 二段階学習(一般蒸留とデータ拡張付きのタスク固有蒸留)は性能向上にとって重要である。
- アテンションベース蒸留は顕著な向上をもたらし、それを隠れ状態蒸留と組み合わせることは補完的である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。