[論文レビュー] TinyLLaVA: A Framework of Small-scale Large Multimodal Models
TinyLLaVA は、データ品質とトレーニング手法を最適化することで、小規模の LMM がより大きなモデルに匹敵できる方法を分析し、1.1–3.1B パラメータのモデル群を提示し、総合ベンチマークで一部の 7B クラスの相当モデルを上回る。
We present the TinyLLaVA framework that provides a unified perspective in designing and analyzing the small-scale Large Multimodal Models (LMMs). We empirically study the effects of different vision encoders, connection modules, language models, training data and training recipes. Our extensive experiments showed that better quality of data combined with better training recipes, smaller LMMs can consistently achieve on-par performances compared to bigger LMMs. Under our framework, we train a family of small-scale LMMs. Our best model, TinyLLaVA-3.1B, achieves better overall performance against existing 7B models such as LLaVA-1.5 and Qwen-VL. We hope our findings can serve as baselines for future research in terms of data scaling, training setups and model selections. Our model weights and codes will be made public.
研究の動機と目的
- 統一された枠組みの下で、視覚エンコーダの選択、コネクタ設計、言語モデルのスケール、データ品質が小規模 LMM に与える影響を評価する。
- 小規模 LMM が、より大きなモデルと競合する、またはそれを上回る性能を発揮するためのトレーニングレシピとデータの組み合わせを特定する。
- リソース制約下で小規模 LMM を設計・訓練するためのベースラインと実践的な指針を提供する。
提案手法
- 視覚エンコーダ、小規模 LLM、コネクタモジュールを備えたモジュール型の TinyLLaVA フレームワークを提案する。
- 2段階の訓練: 画像キャプション風データを用いた特徴整列の事前訓練、続いて多ターンの画像-テキスト対話での教師ありファインチューニング。
- 2つの訓練レシピ: base(視覚エンコーダを凍結; コネクタと LLM を訓練)と share(視覚エンコーダの最初の 12 層を凍結; より多くのパラメータをファインチューニング)。
- LLM のバックボーン(TinyLlama、StableLM-2、Phi-2)、視覚エンコーダ(CLIP、SigLIP)、コネクタ(MLP 対 Resampler)を変えた実験。
- VQA/GQA/SQA I/ TextVQA および総合ベンチマーク(POPE、MM-Vet、LLaVA-W、MME、MMBench)で評価。
- TinyLLaVA 変種の競争力を評価するため、SOTA LMMs との比較。
実験結果
リサーチクエスチョン
- RQ1TinyLLaVA における異なる視覚エンコーダと小型 LLM バックボーンが多模態理解に与える影響はどのようなものか?
- RQ2訓練データの品質と規模が小規模 LMM の性能に与える影響はどの程度か?
- RQ3より多くのパラメータをファインチューニングする訓練レシピは、ベンチマーク全体で小規模 LMM に利益をもたらすのか、それとも悪化させるのか?
- RQ4TinyLLaVA の変種は、7B+ モデルより著しく少ないパラメータで競争力のある性能を達成できるか?
主な発見
| 手法 | LLM | サイズ | 解像度 | VQA v2 | GQA | SQA I | VQA T | MM-Vet | POPE | LLaVA-W | MME | MMBench |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I-9B | L-7B | 9B | 224 | 50.9 | 38.4 | - | 25.9 | - | - | - | - | 48.2 |
| InstructBLIP | V-7B | 8.2B | 224 | - | 49.2 | 60.5 | 50.1 | 26.2 | - | 60.9 | - | 36 |
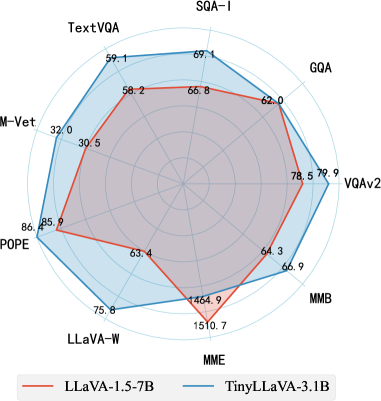
| LLaVA-1.5 | V-7B | 7B | 336 | 78.5* | 62.0* | 66.8 | 58.2 | 30.5 | 85.9 | 63.4 | 1510.7 | 64.3 |
| Qwen-VL | Q-7B | 7B | 448 | 78.8* | 59.3* | 67.1 | 63.8 | - | - | - | - | 38.2 |
| MoE-LLaVA | Phi2-2.7B | 3.9B | 336 | 77.6* | 61.4* | 68.5 | 51.4 | 34.3 | 86.3 | 94.1 | - | 65.5 |
| MoE-LLaVA | Phi2-2.7B | 3.9B | 384 | 79.9* | 62.6* | 70.3 | 57.0 | 35.9 | 85.7 | 97.3 | - | 68.0 |
| LLaVA-Phi | Phi2-2.7B | 3.0B | 336 | 71.4* | - | 68.4 | 48.6 | 28.9 | 85.0 | - | 1335.1 | 59.8 |
| MobileVLM | ML-2.7B | 3.0B | 336 | - | 59.0* | 61.0 | 47.5 | - | 84.9 | - | 1288.9 | 59.6 |
| TinyLLaVA-share-C-Phi | Phi2-2.7B | 3.0B | 336 | 77.7* | 61.0* | 70.1 | 53.5 | 31.7 | 86.3 | 67.1 | 1437.3 | 68.3 |
| TinyLLaVA-share-Sig-Phi | Phi2-2.7B | 3.1B | 384 | 79.9* | 62.0* | 69.1 | 59.1 | 32.0 | 86.4 | 75.8 | 1464.9 | 66.9 |
- 高品質なデータと効果的な訓練レシピと組み合わせた場合、小規模 LMM は大規模な相手と同等以上の性能を達成できる。
- 視覚エンコーダとして SigLIP は CLIP より顕著な利得をもたらす。入力解像度が高く、視覚トークンが多いためと考えられる。
- Phi-2 は小型 LLM バックボーンの中で一般的に高い性能を示し、より多くのパラメータ数の恩恵を受けている。
- share 訓練レシピは、特により大きく多様な事前訓練データと組み合わせると、いくつかの変種の性能を向上させるが、いくつかのバックボーンでは幻覚の増加を招くことがある。
- 適切なデータ/レシピを用いた TinyLLaVA-3.1B は、集合指標で LLaVA-1.5 や Qwen-VL などの既存の 7B モデルを上回る。
- より小さな LLM を用いる TinyLLaVA 変種は、大規模データに適合させるために事前訓練中により多くの訓練可能パラメータを必要とする場合があり、一方で大きな LLM はより多くのパラメータを訓練すると幻覚を起こしやすくなることがある。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。