[論文レビュー] Titans: Learning to Memorize at Test Time
Titans は、テスト時に記憶を学習する深層ニューラル長期メモリモジュールを導入し、それをコアの注意ベースのアーキテクチャと統合して極端に長い文脈を扱い、Transformersおよび線形再帰モデルを多様なタスクで上回る。
Over more than a decade there has been an extensive research effort on how to effectively utilize recurrent models and attention. While recurrent models aim to compress the data into a fixed-size memory (called hidden state), attention allows attending to the entire context window, capturing the direct dependencies of all tokens. This more accurate modeling of dependencies, however, comes with a quadratic cost, limiting the model to a fixed-length context. We present a new neural long-term memory module that learns to memorize historical context and helps attention to attend to the current context while utilizing long past information. We show that this neural memory has the advantage of fast parallelizable training while maintaining a fast inference. From a memory perspective, we argue that attention due to its limited context but accurate dependency modeling performs as a short-term memory, while neural memory due to its ability to memorize the data, acts as a long-term, more persistent, memory. Based on these two modules, we introduce a new family of architectures, called Titans, and present three variants to address how one can effectively incorporate memory into this architecture. Our experimental results on language modeling, common-sense reasoning, genomics, and time series tasks show that Titans are more effective than Transformers and recent modern linear recurrent models. They further can effectively scale to larger than 2M context window size with higher accuracy in needle-in-haystack tasks compared to baselines.
研究の動機と目的
- 短期の注意機構と長期的な記憶を組み合わせるメモリシステムの設計を動機づける。
- サプライズ駆動機構に基づいてテスト時に更新されるニューラル長期記憶を提案する。
- 高速で並列化可能な方法で長期記憶を訓練し、検索する方法を示す。
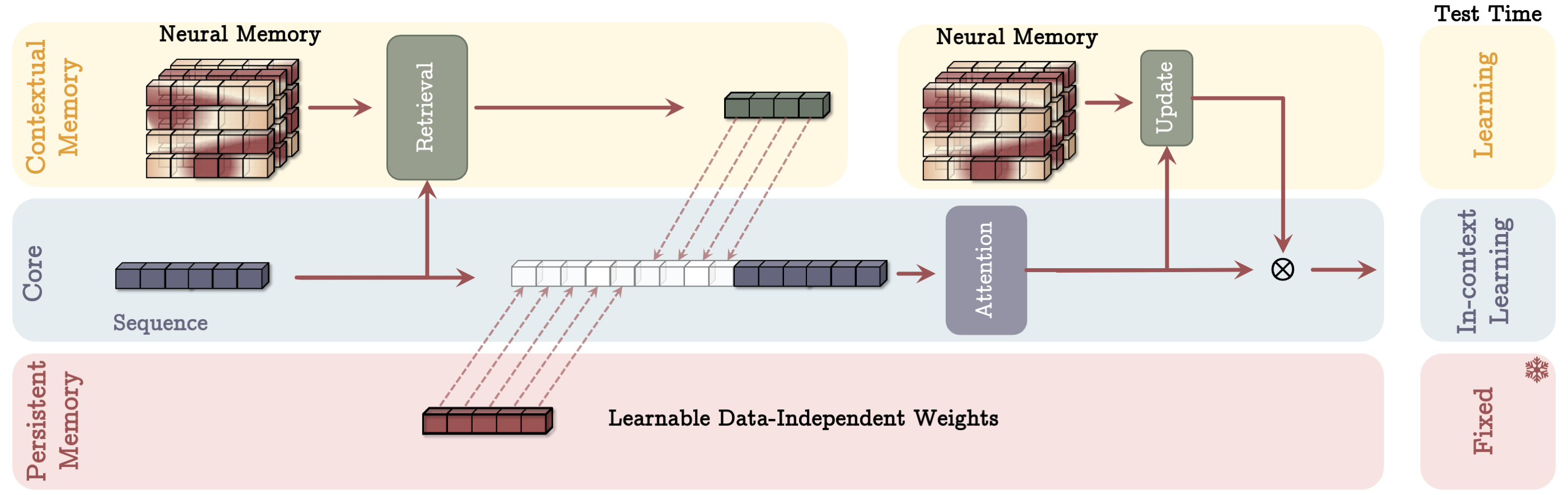
- 三分岐の Titans アーキテクチャ(Core、Long-term Memory、Persistent Memory)と長期記憶を統合する。
- さまざまなタスクにおいて、2 million tokens を超えるコンテキスト窓へのスケーラビリティを示す。
提案手法
- サプライズ駆動更新を用いて過去情報をパラメータに格納するニューラル長期記憶モジュールを導入する。
- サプライズを、入力に対する損失の勾配を用いて定義し、データ依存の減衰を伴う過去のサプライズと現在のサプライズに分解する。
- キー–バリュー対の連想記憶損失を用いてメモリを訓練するメタ学習風の内部ループを使用する。
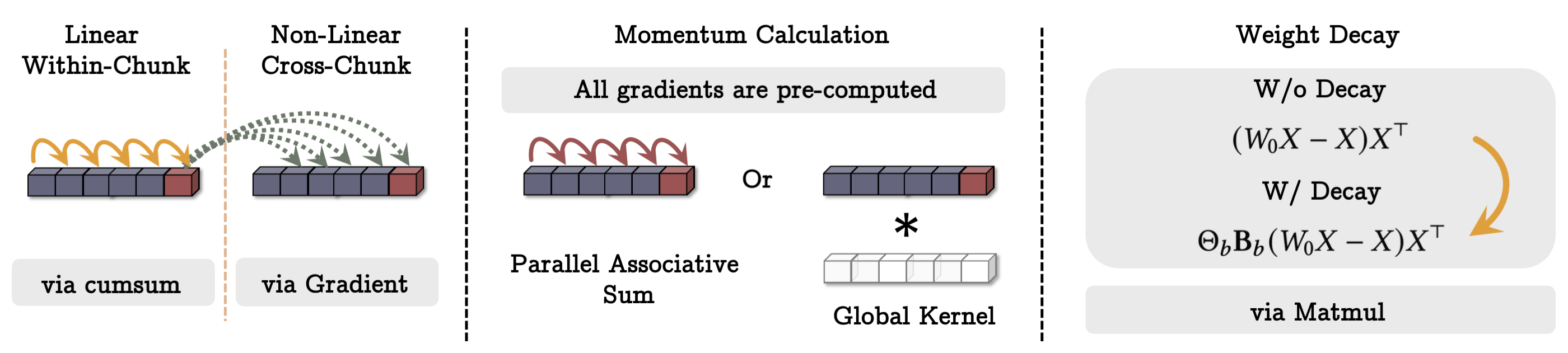
- 並列性のためにミニバッチ勾配降下法と行列積ベースの計算を用いる高速なテンソル化訓練方式を提案する。
- タスク関連でデータに依存しない Persistent Memory を組み込み、メモリがコンテキスト、層、ゲート付き分岐として使用される3つの Titans バリアントを提示する。
実験結果
リサーチクエスチョン
- RQ1長期依存性に対して効果的なメモリ構造とは何か?
- RQ2長い系列に渡る暗記と忘却を最もよく支援するメモリ更新機構は何か?
- RQ3現在のタスクに関連する保存情報を効率的に抽出する検索プロセスは何か?
- RQ4トレーニング/推論速度を犠牲にすることなく、メモリモジュールをアーキテクチャに効率的に統合するにはどうすればよいか?
- RQ5堅牢な長期記憶のためには深層ニューラル長期記憶が必要か?
主な発見
- Titans は言語モデリング、推論、ゲノミクス、時系列タスクにおいて、最新の再帰モデルおよびそれらのハイブリッドを上回る。
- Titans は 2M tokens を超えるコンテキスト窓へとスケール可能で、ベースラインと比較して needle-in-haystack タスクでより高い精度を示す。
- 長期記憶モジュールはサプライズ駆動更新と忘却機構を利用して、メモリ管理と一般化を改善する。
- テンソル化されたミニバッチ更新による並列化トレーニングは、深い記憶の効率的な訓練を可能にする。
- Persistent memory は入力に依存しないタスク知識を提供し、学習と検索を安定化させる。
- 3つの Titans バリアント(Memory as Context、Memory as Gate、ゲーティングベースの設計)は、効率と有効性のトレードオフを提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。