[論文レビュー] TopicGPT: A Prompt-based Topic Modeling Framework
TopicGPTはプロンプトベースの大規模言語モデルを用いてテキストコーパスから解釈可能なトピックを生成・割り当て、人間の真実のトピックとLDAおよびBERTopicより高い整合性を達成し、再学習なしでトピックの精緻化と階層化をサポートします。
Topic modeling is a well-established technique for exploring text corpora. Conventional topic models (e.g., LDA) represent topics as bags of words that often require "reading the tea leaves" to interpret; additionally, they offer users minimal control over the formatting and specificity of resulting topics. To tackle these issues, we introduce TopicGPT, a prompt-based framework that uses large language models (LLMs) to uncover latent topics in a text collection. TopicGPT produces topics that align better with human categorizations compared to competing methods: it achieves a harmonic mean purity of 0.74 against human-annotated Wikipedia topics compared to 0.64 for the strongest baseline. Its topics are also interpretable, dispensing with ambiguous bags of words in favor of topics with natural language labels and associated free-form descriptions. Moreover, the framework is highly adaptable, allowing users to specify constraints and modify topics without the need for model retraining. By streamlining access to high-quality and interpretable topics, TopicGPT represents a compelling, human-centered approach to topic modeling.
研究の動機と目的
- 人間中心のトピックモデリングフレームワークを開発し、自然言語ラベルと説明を伴う解釈可能なトピックを提供する。
- 再学習なしでドキュメントのサンプルからトピックを生成・改良するために反復的なLLM promptingを活用する。
- 証拠となる引用を伴うドキュメント-トピック割り当てを提供して結果の検証性を高める。
- 必要に応じて関連ドキュメントに基づくサブトピックを探る階層拡張を可能にする。
- 人間の注釈と一致する健全さ・安定性・整合性を評価する。
提案手法
- サンプルのドキュメントと既存のシードトピックからトピックを生成するためにLLMを反復的に prompting。
- 埋め込みと頻度閾値を用いて近接重複を統合し、頻度の低いトピックを除去してトピックを洗練する。
- 関連ドキュメントに基づくサブトピックを prompting して階層を拡張するオプション。
- トピックラベル・説明・引用をサポートとして返すトピックを割り当てるためのLLMプロンプトを用いてドキュメントをトピックに割り当てる。
- トピック割り当ての幻覚やフォーマットの問題を修正する自己訂正ステップを組み込む。
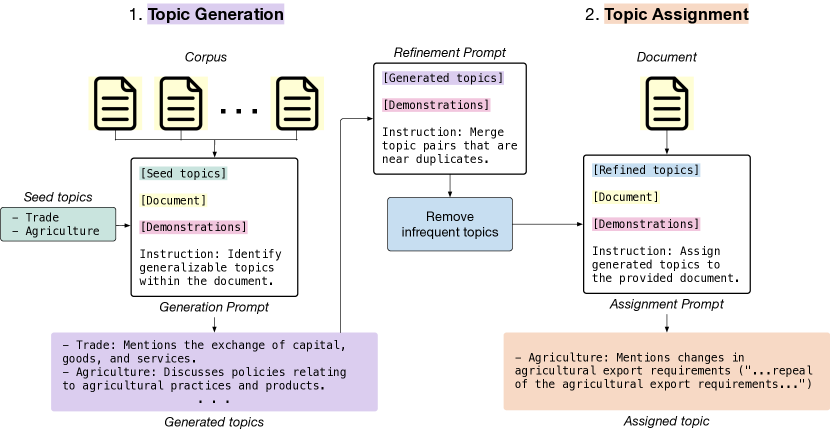
実験結果
リサーチクエスチョン
- RQ1TopicGPT生成のトピックは、LDAとBERTopicよりデータセット全体で人間が注釈した真実トピックとより近い整合性を示すか?
- RQ2プロンプト変 variations, サンプル選択、およびオープン対クローズドソースLLMに対してTopicGPTの出力はどれくらい頑健か?
- RQ3TopicGPTは割り当てをサポートする自然言語ラベルと説明的引用を伴う解釈可能なトピックを信頼性高く生成できるか?
- RQ4TopicGPTを階層構造に拡張することでトピックの粒度と有用性は向上するか?
- RQ5シードトピックの品質と量はトピックの一貫性と整合性にどんな影響を与えるか?
主な発見
| データセット | 設定 | TopicGPT P1 | TopicGPT ARI | TopicGPT NMI | LDA P1 | LDA ARI | LDA NMI | BERTopic P1 | BERTopic ARI | BERTopic NMI |
|---|---|---|---|---|---|---|---|---|---|---|
| Wiki | Default (k=31) | 0.73 | 0.58 | 0.71 | 0.71 | 0.59 | 0.65 | 0.44 | 0.65 | 0.50 |
| Wiki | Refined (k=22) | 0.74 | 0.60 | 0.70 | 0.70 | 0.64 | 0.67 | 0.52 | 0.58 | 0.50 |
| Bills | Default (k=79) | 0.57 | 0.42 | 0.47 | 0.52 | 0.39 | 0.47 | 0.21 | 0.47 | 0.40 |
| Bills | Refined (k=24) | 0.57 | 0.40 | 0.46 | 0.52 | 0.32 | 0.46 | 0.39 | 0.12 | 0.34 |
- TopicGPTはWikiとBillsデータセットでLDAとBERTopicより真実ラベルとのトピック整合性が高い(例: Wiki P1=0.73, ARI=0.58, NMI=0.71; Bills P1=0.57, ARI=0.42, NMI=0.47 デフォルト設定)。
- 洗練は解釈性を高め、整合していないトピックを減らす(例: 洗練後 Wiki P1=0.74, ARI=0.60; 洗練後 Bills P1=0.57, ARI=0.40)。
- TopicGPTの割り当てはさまざまなプロンプトやデータサンプルでも安定しており、整合性指標でLDAと同等またはそれ以上の性能を示す;パイプラインを2回実行すると高い安定性が得られる(P1=0.95, ARI=0.92, NMI=0.92)。
- オープンソースLLMはトピック割り付けには対応できるが(例: Mistral-7B-Instructは割り付けで概して良好)、トピック生成ではオープンソースモデルはGPT-4と比べて苦戦する。
- TopicGPTは未洗練・洗練後の両方でLDAより真のトピックに意味的に近いトピックを生成し、洗練は大幅に誤配列を減らす。
- Hierarchical TopicGPTは親トピックとそのドキュメントに基づく有益なサブトピックを生成でき、より豊富な分析を可能にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。