[論文レビュー] Towards A Unified Agent with Foundation Models
本論文は、視覚-言語モデルと大規模言語モデルを用いて、スパース報酬のロボット積み重ねタスクを解決する言語中心の強化学習フレームワークを提示し、探索の効率化、データ再利用、スキルスケジューリング、およびタスク特異的な手作りカリキュラムなしでの観察からの学習を可能にする。
Language Models and Vision Language Models have recently demonstrated unprecedented capabilities in terms of understanding human intentions, reasoning, scene understanding, and planning-like behaviour, in text form, among many others. In this work, we investigate how to embed and leverage such abilities in Reinforcement Learning (RL) agents. We design a framework that uses language as the core reasoning tool, exploring how this enables an agent to tackle a series of fundamental RL challenges, such as efficient exploration, reusing experience data, scheduling skills, and learning from observations, which traditionally require separate, vertically designed algorithms. We test our method on a sparse-reward simulated robotic manipulation environment, where a robot needs to stack a set of objects. We demonstrate substantial performance improvements over baselines in exploration efficiency and ability to reuse data from offline datasets, and illustrate how to reuse learned skills to solve novel tasks or imitate videos of human experts.
研究の動機と目的
- 基盤モデルが強化学習エージェントの統一的な推論バックボーンとして機能する方法を探る。
- 疎報酬環境における探索効率の改善を実証する。
- オフラインデータを再利用して逐次タスク学習をブートストラップする方法を示す。
- 言語に基づくゴールを通じたスキルスケジューリングと観察からの学習を示す。
提案手法
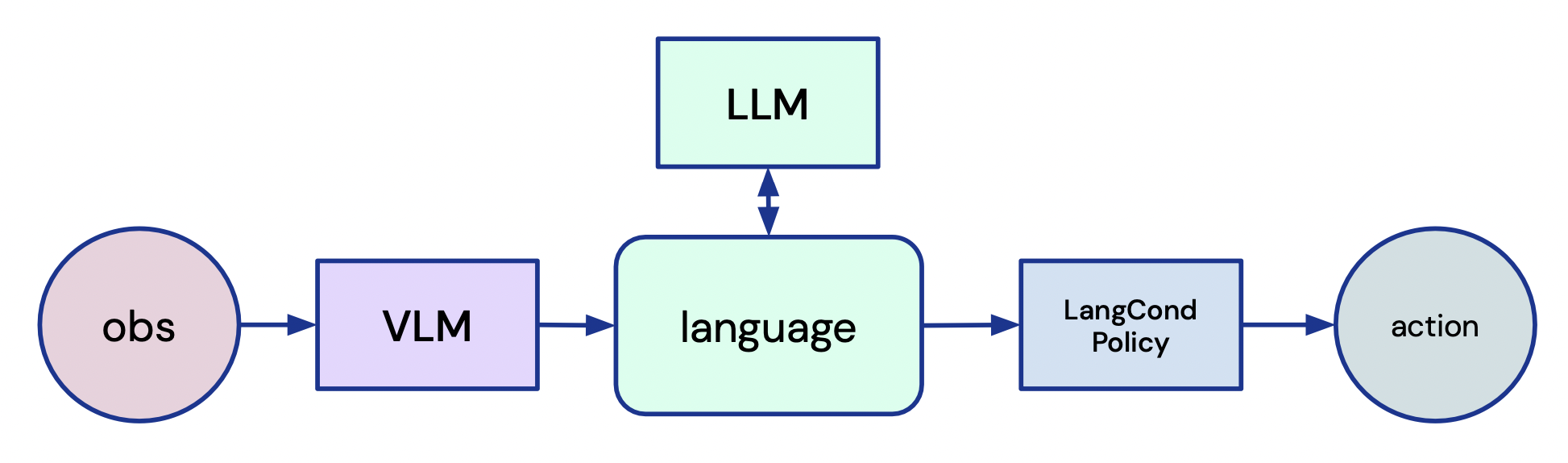
- 観察をCLIP風の埋め込みで記述して映像とテキストを対応付け、視覚と言語を橋渡しする。
- 事前学習済みのLLMをファインチューニングしたFLAN-T5を用いて、追加のイン-domainトレーニングなしでタスクをテキストのサブゴールに分解する。
- 言語のサブゴールを、RLでゼロから学習したトランスフォーマーベースの言語条件付きポリシーを介して行動へ落とし込む。
- 観察に基づくサブゴール完了を検証して内部報酬を提供するCollect & Infer ループを採用する。
- データを共有バッファに収集する分散エージェントを複数運用し、エピソード後に行動クローンを実行する(N=1000)。
- VLMベースの報酬再ラベリングとCLIP風のグラウンディングを用いて過去の経験を新しいタスクに結びつけ、オフラインデータの再利用を可能にする。
- 専門家のビデオフレームをVLMを介してサブゴールにマッピングし、対応するスキルを実行することで観察からの学習をサポートする。
実験結果
リサーチクエスチョン
- RQ1基盤モデル(LLMs/VLMs)は、疎報酬設定におけるコアな RL 課題に対して統一的なアプローチを提供できるか。
- RQ2手作りの報酬なしで、言語生成のサブゴールが探索とカリキュラム生成をどれだけ効果的に guiding できるか。
- RQ3ロボット操作における逐次タスクの学習をブートストラップするために、オフラインの経験をどの程度再利用できるか。
- RQ4学習したスキルをスケジューリングして再利用し、未知のタスクを解決し観察からの学習を可能にできるか。
主な発見
- 本フレームワークは、Stack Red on Blue および Triple Stack タスクにおいて、環境報酬のみのベースラインエージェントより著しく学習が速くなる。
- Triple Stack タスクは、ベースラインが極端なスパース性(sparseness > 10^6)により停止する中、迅速な学習を示す。
- 単一のフレームワークで、ドメイン特化の報酬設計なしに言語主導のカリキュラムによる探索を実現する。
- 前のタスクのオフラインデータを再ラベル付けして再利用し、新しいタスクをブートストラップして逐次タスク学習を加速する。
- 動画を用いた観察学習により、学習したスキルをサブゴールへグラウンディングし、新しい文脈で実行できるようにする。
- 自己模倣を伴う分散データ収集(N=1000エージェント)は、サンプル効率と学習の安定性を向上させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。