[論文レビュー] Towards Anatomy Education with Generative AI-based Virtual Assistants in Immersive Virtual Reality Environments
この研究は、ジェネレーティブAIを具現化した仮想アシスタント(アバター対スクリーン)を備えたVR解剖教育環境を提示し、16名の参加者を対象としたプレ pilotで、二つの認知複雑性レベルにおけるユーザーのパフォーマンス、使いやすさ、プレゼンスを評価します。
Virtual reality (VR) and interactive 3D visualization systems have enhanced educational experiences and environments, particularly in complicated subjects such as anatomy education. VR-based systems surpass the potential limitations of traditional training approaches in facilitating interactive engagement among students. However, research on embodied virtual assistants that leverage generative artificial intelligence (AI) and verbal communication in the anatomy education context is underrepresented. In this work, we introduce a VR environment with a generative AI-embodied virtual assistant to support participants in responding to varying cognitive complexity anatomy questions and enable verbal communication. We assessed the technical efficacy and usability of the proposed environment in a pilot user study with 16 participants. We conducted a within-subject design for virtual assistant configuration (avatar- and screen-based), with two levels of cognitive complexity (knowledge- and analysis-based). The results reveal a significant difference in the scores obtained from knowledge- and analysis-based questions in relation to avatar configuration. Moreover, results provide insights into usability, cognitive task load, and the sense of presence in the proposed virtual assistant configurations. Our environment and results of the pilot study offer potential benefits and future research directions beyond medical education, using generative AI and embodied virtual agents as customized virtual conversational assistants.
研究の動機と目的
- ジェネレーティブAIを具現化VRと統合して口頭での対話と適応的質問を支援することで解剖教育を進化させる。
- VRにおけるアバターおよびスクリーンベースAIアシスタントの技術的有効性と使いやすさを認知複雑性の異なる場合で評価する。
- 同一課題内デザインでユーザー体験指標(使いやすさ、タスク負荷、プレゼンス)とパフォーマンスを評価する。
- AI対応VR解剖教育の利点、限界、将来の研究方向性を特定する。
提案手法
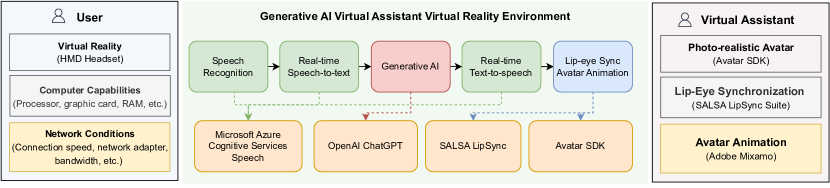
- ChatGPT-3.5–driven embodied virtual assistantを備えたUnityベースの没入型VR解剖環境を開発した。
- 2x2の同一被験者デザインで2つの相互作用構成(リップシンクされた音声付きのアバター vs テキストのみのスクリーン)を比較した。
- 質問にはBloomの taxonomyの知識ベースと分析ベースの2つの認知レベルを実装した。
- 客観的パフォーマンスデータ(タスク完了時間、相互作用回数、スコア)と主観的指標(SUS、NASA TLX、IPQ)を収集した。
- 構成、認知レベル、相互作用効果を評価するために2要因ANOVAでデータを分析した。
実験結果
リサーチクエスチョン
- RQ1RQ1 アバターベースとスクリーンベースの仮想アシスタント構成は解剖教育におけるユーザーパフォーマンスにどのような影響を与えるか?
- RQ2RQ2 主観的指標(使いやすさ、タスク負荷、プレゼンス)は仮想アシスタント構成とどのように関連するか?
- RQ3RQ3 ジェネレーティブAIを解剖教育に用いる利点、限界、潜在的な研究方向は何か?
主な発見
| Variable | Task Completion Time (s) | Number of Interactions | Scores |
|---|---|---|---|
| Avatar Total | 159.23 (149.25) [26.38] | 5.96 (11.87) [2.10] | 0.59 (0.49) [0.08] |
| Knowledge-based (Avatar) | 117.74 (72.61) [18.15] | 5.31 (11.22) [2.80] | 0.75 (0.44) [0.11] |
| Analysis-based (Avatar) | 200.72 (192.59) [48.14] | 6.62 (12.83) [3.20] | 0.43 (0.51) [0.12] |
| Screen Total | 159.06 (152.94) [27.03] | 3.65 (2.74) [0.48] | 0.50 (0.50) [0.09] |
| Knowledge-based (Screen) | 177.50 (200.57) [50.14] | 4.31 (3.36) [0.84] | 0.56 (0.51) [0.12] |
| Analysis-based (Screen) | 140.62 (85.96) [21.49] | 3.00 (1.82) [0.45] | 0.43 (0.51) [0.12] |
- アバター構成は全体的により高いスコアを生み出し、知識ベースと分析ベースの質問間のばらつきが大きかった(アバター内の認知レベルで有意差、F(1,15)=4.62, p=0.046, ηp2=0.07)。
- 知識ベースの質問はアバター構成で分析ベースの質問より迅速に回答され、やり取り回数が少なく、認知的複雑性の影響を示す。
- 使いやすさは両構成とも高く(アバター SUS 75.16、スクリーン SUS 76.72)、構成間に有意差はなし。
- タスク負荷は構成間で有意差なし、精神的要求が両方で最も高く評価された次元。
- プレゼンスのスコアは構成間で類似しており、IPQ結果に有意差はなし。
- 定性的フィードバックはアバター対スクリーンに対する好みが混在しており、声の同期や質問表現戦略の改善を求める声があった。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。