[論文レビュー] Towards Building Multilingual Language Model for Medicine
本論文は MMedC、25.5Bトークンの多言語医療コーパス、評価ベンチマーク MMedBench、オープンソースの多言語医療LLM(MMedLM/MMedLM 2)を導入し、MMedBenchにおいてGPT-4と対等以上の強力な性能を発揮する。
The development of open-source, multilingual medical language models can benefit a wide, linguistically diverse audience from different regions. To promote this domain, we present contributions from the following: First, we construct a multilingual medical corpus, containing approximately 25.5B tokens encompassing 6 main languages, termed as MMedC, enabling auto-regressive domain adaptation for general LLMs; Second, to monitor the development of multilingual medical LLMs, we propose a multilingual medical multi-choice question-answering benchmark with rationale, termed as MMedBench; Third, we have assessed a number of open-source large language models (LLMs) on our benchmark, along with those further auto-regressive trained on MMedC. Our final model, MMed-Llama 3, with only 8B parameters, achieves superior performance compared to all other open-source models on both MMedBench and English benchmarks, even rivaling GPT-4. In conclusion, in this work, we present a large-scale corpus, a benchmark and a series of models to support the development of multilingual medical LLMs.
研究の動機と目的
- 開発言語的に多様な聴衆に対応するオープンソースの多言語医療言語モデルを作成する。
- 六つの言語にまたがる自己回帰トレーニングのための大規模な多言語医療コーパス(MMedC)を構築する。
- 多言語医療推論を評価するための多言語医療QAベンチマーク(MMedBench)を作成し、その設計根拠を示す。
- MMedCで訓練されたオープンソースLLMおよびモデル(MMedLM/MMedLM 2)の評価を通じて、多言語医療QAと推論生成を評価する。
提案手法
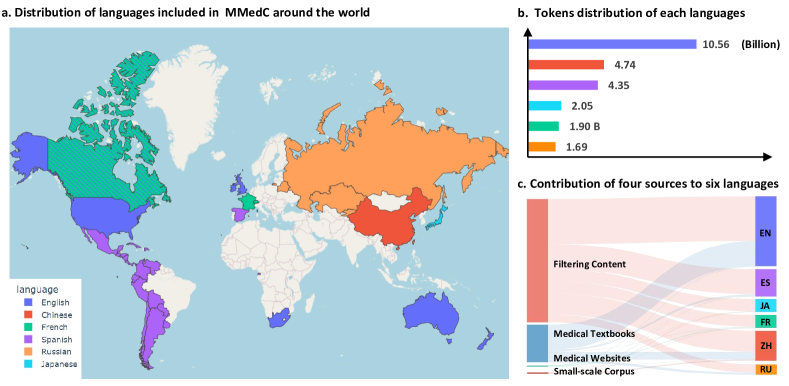
- 英語、中国語、日本語、フランス語、ロシア語、スペイン語の4つのデータソースから、合計 over 25.5B トークンのMMedCを構築する。
- 多言語医療の択一式QAデータセットを集約し、GPT-4が生成した推論を付加してMMedBenchを作成する。
- MMedCで訓練されたモデル(MMedLM/MMedLM 2)を含むさまざまなLLMを、ゼロショット、PEFT、全ファインチューニング設定で微調整および評価する。
- 自動指標(BLEU-1, ROUGE-1, BERT-score)と人間評価を用いて推論の品質を評価し、信頼性の高い評価手法を特定する。
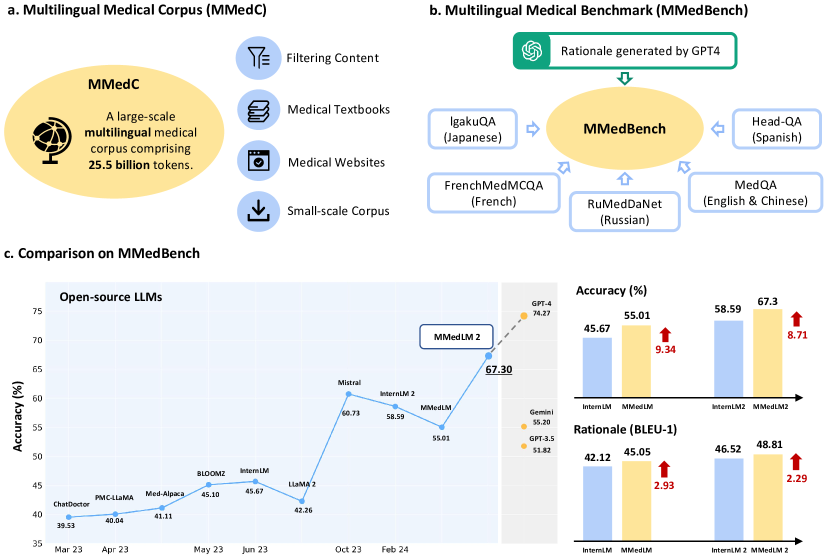
実験結果
リサーチクエスチョン
- RQ1多言語の医療中心コーパスは、非英語の医療クエリに対してオープンソースのLLMを改善できるか。
- RQ2MMedCでの訓練は、六言語にわたる医療QAと推論生成にどのような影響を与えるか。
- RQ3多言語のLLMにおける医療推論の人間判断を最もよく反映する評価指標はどれか。
- RQ4MMedBenchにおけるオープンソースの多言語医療LLMとクローズドソースモデルの比較性能はどうなるか。
主な発見
| 方法 | サイズ | 年 | MMedC | MMedBench | English | Chinese | Japanese | French | Russian | Spanish | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-3.5 | - | 2022.12 | ✗ | ✗ | 56.88 | 52.29 | 34.63 | 32.48 | 66.36 | 66.06 | 51.47 |
| GPT-4 | - | 2023.3 | ✗ | ✗ | 78.00 | 75.07 | 72.91 | 56.59 | 83.62 | 85.67 | 74.27 |
| Gemini-1.0 pro | - | 2024.1 | ✗ | ✗ | 53.73 | 60.19 | 44.22 | 29.90 | 73.44 | 69.69 | 55.20 |
| BLOOMZ | 7B | 2023.5 | ✗ | trainset | 38.88 | 48.86 | 17.59 | 18.65 | 53.91 | 44.78 | 37.11 |
| InternLM | 7B | 2023.7 | ✗ | trainset | 40.93 | 52.19 | 27.14 | 18.81 | 46.88 | 40.34 | 37.71 |
| Llama2 | 7B | 2023.7 | ✗ | trainset | 37.00 | 37.13 | 24.12 | 19.13 | 63.67 | 42.89 | 37.32 |
| ChatDoctor | 7B | 2023.3 | ✗ | trainset | 36.68 | 34.06 | 28.14 | 11.58 | 60.55 | 39.86 | 35.15 |
| MedAlpaca | 7B | 2023.4 | ✗ | trainset | 43.28 | 36.81 | 27.14 | 16.40 | 51.95 | 41.72 | 36.22 |
| PMC-LLaMA | 7B | 2023.4 | ✗ | trainset | 33.62 | 31.76 | 20.60 | 10.13 | 57.81 | 37.89 | 31.97 |
| Mistral | 7B | 2023.10 | ✗ | trainset | 55.38 | 50.23 | 37.69 | 40.19 | 71.88 | 61.60 | 52.83 |
| InternLM 2 | 7B | 2024.2 | ✗ | trainset | 52.40 | 68.18 | 39.20 | 28.78 | 63.67 | 55.25 | 51.25 |
| MMedLM (Ours) | 7B | - | ✔ | trainset | 41.16 | 52.22 | 27.14 | 18.49 | 47.66 | 40.34 | 37.83 |
| MMedLM 2 (Ours) | 7B | - | ✔ | trainset | 58.13 | 70.43 | 54.27 | 38.26 | 71.88 | 64.95 | 59.65 |
- MMedCで訓練されたモデル(MMedLM、MMedLM 2)はベースラインを上回り、MMedBenchの複数の設定でGPT-4に対抗できる。
- 6言語にわたり、MMedLM 2は multilingual full fine-tuningで英語からスペイン語までの精度が58.13%〜80.01%、平均67.30%を達成した。
- 推論生成はMMedCでの訓練によって改善され、BLEU-1およびROUGE-1スコアと人間評価でMMedLM 2が有利となった。
- ROUGE-1とBLEU-1はMMedBenchの推論評価における信頼性の高い自動指標として特定され、GPT-4の評価は人間判断と最も相関する一方で、スケーリングが難しい。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。