[論文レビュー] Towards Coding Social Science Datasets with Language Models
GPT-3は社会科学テキストのコーディングにおける合成コーダーとして機能し、人間のコーダーと同等を達成し、 supervised MLと競合する。少数ショットプロンプトを用いた多様なタスクで高い効率を示す。
Researchers often rely on humans to code (label, annotate, etc.) large sets of texts. This kind of human coding forms an important part of social science research, yet the coding process is both resource intensive and highly variable from application to application. In some cases, efforts to automate this process have achieved human-level accuracies, but to achieve this, these attempts frequently rely on thousands of hand-labeled training examples, which makes them inapplicable to small-scale research studies and costly for large ones. Recent advances in a specific kind of artificial intelligence tool - language models (LMs) - provide a solution to this problem. Work in computer science makes it clear that LMs are able to classify text, without the cost (in financial terms and human effort) of alternative methods. To demonstrate the possibilities of LMs in this area of political science, we use GPT-3, one of the most advanced LMs, as a synthetic coder and compare it to human coders. We find that GPT-3 can match the performance of typical human coders and offers benefits over other machine learning methods of coding text. We find this across a variety of domains using very different coding procedures. This provides exciting evidence that language models can serve as a critical advance in the coding of open-ended texts in a variety of applications.
研究の動機と目的
- 社会科学のテキストコーディングにおけるコストとばらつきを減らすため、言語モデルによる人間のコーディングの置換または補完を動機づける。
- GPT-3がファイン tuning なしで多様なデータセットとコーディングスキームを横断してコーディングする能力を示す。
- GPT-3のコーディング性能を人間のコーダーおよび従来の教師ありMLアプローチと比較する。
- GPT-3コーディングの信頼性(インコーダー合意)と効率性(時間/コスト)をタスク横断で評価する。
提案手法
- GPT-3へタスク固有のプロンプトを2〜3の exemplarsとともに提供してコーディングタスクを教示する。
- GPT-3の出力をカテゴリカルまたは序数コードへ変換し、インターコーダ信頼性指標を用いて人間のコーダーと比較する。
- 四つのデータセット(PP, CAP-Congress, CAP-NYT, TGP)を用いて、領域、データ構造、測定タイプを横断してコーディングを検証する。
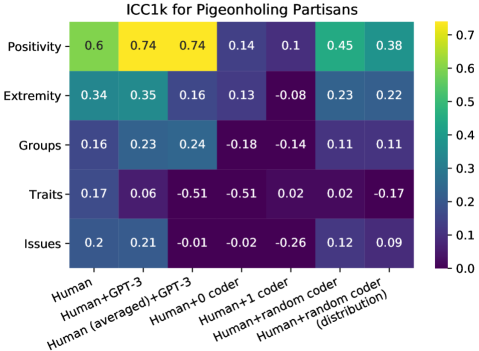
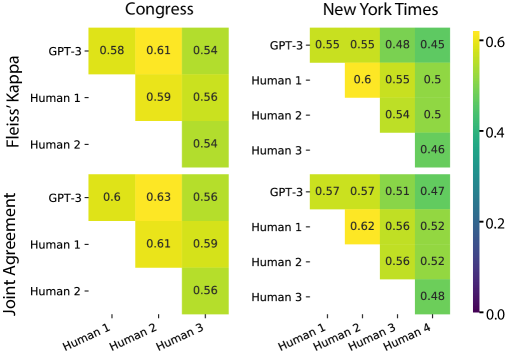
- GPT-3と人間の間の同意を定量化するために、Intraclass Correlation (ICC)、joint probability of agreement、およびFleiss’ kappaを計算する。
- 複数のカテゴリが可能な場合にモデルバイアスを補正するためにGPT-3のカテゴリ確率をキャリブレーションする(任意、控えめな利得)。
実験結果
リサーチクエスチョン
- RQ1GPT-3はファイネ tuningなしでfew-shotプロンプトを用い、社会科学テキストを人間のコーダーと同等の性能でコーディングできるか。
- RQ2GPT-3のコーディング信頼性(ICC、kappa、joint agreement)は、多様なデータセットにわたって人間のコーダーおよび教師あり機械学習ベースラインと比較してどうか。
- RQ3プロンプト設計と exemplar の選択は、GPT-3のコーディング精度と信頼性に意味のある影響を与えるか。
- RQ4大規模なテキストコーディングにおけるGPT-3の効率性とコストは、従来の人間またはMLアプローチと比較してどうか。
- RQ5GPT-3のコーディング性能には、人間と比較してドメイン固有またはカテゴリ固有のパターンがあるか。
主な発見
- GPT-3は、ordinalおよびcategoricalなコーディングタスクで、わずか2–3 exemplarsで人間のコーダーの性能に匹敵する。
- GPT-3は、いくつかの属性で人間のみのコーディングと比較してインターコーダ信頼性(ICC)を高めることが多いが、すべてのカテゴリで一様ではない。
- GPT-3の性能は教師ありMLベースラインと競争力があり、非常に少ないラベル付き例数(例: 4 exemplars vs thousands)で substantial accuracy を達成。
- 4つのデータセット(PP, CAP-Congress, CAP-NYT, TGP)を通じて、GPT-3の人間との同意は多くのケースで人間対人間の同意と同等であるが、タスクおよびカテゴリによって変動がある。
- GPT-3の確率のキャリブレーションは modestな精度向上をもたらす可能性がある(≈4–5%)。
- Guardian Populismデータで、GPT-3は人間と0.77 ICC(人間は0.81)程度、4 exemplarsを用いて人間のコーディング精度の約79%を達成する一方、bag-of-words MLアプローチは thousandsのラベル付き例で約86%に達する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。