[論文レビュー] Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
本論文は生成型 LLMs の効率的な提供を概観し、デコード技術からハードウェア対応アーキテクチャと量子化に至るアルゴリズム上の革新とシステム最適化をカバーし、将来の研究方向を概説する。
In the rapidly evolving landscape of artificial intelligence (AI), generative large language models (LLMs) stand at the forefront, revolutionizing how we interact with our data. However, the computational intensity and memory consumption of deploying these models present substantial challenges in terms of serving efficiency, particularly in scenarios demanding low latency and high throughput. This survey addresses the imperative need for efficient LLM serving methodologies from a machine learning system (MLSys) research perspective, standing at the crux of advanced AI innovations and practical system optimizations. We provide in-depth analysis, covering a spectrum of solutions, ranging from cutting-edge algorithmic modifications to groundbreaking changes in system designs. The survey aims to provide a comprehensive understanding of the current state and future directions in efficient LLM serving, offering valuable insights for researchers and practitioners in overcoming the barriers of effective LLM deployment, thereby reshaping the future of AI.
研究の動機と目的
- LLM の提供と推論の進展を包括的に概説する。
- 技術を基盤となるアプローチ(アルゴリズム対システム)で分類し、それぞれの長所と短所を分析する。
- デコード、アーキテクチャ設計、モデル圧縮、低ビット量子化、並列計算、メモリ管理、カーネル最適化を検討する。
- 今後の研究と実践を導くために代表的な LLM 提供フレームワークとベンチマークを調査する。
提案手法
- アルゴリズムの革新とシステム最適化を分離した、効率的な LLM 提供アプローチの分類法を開発する。
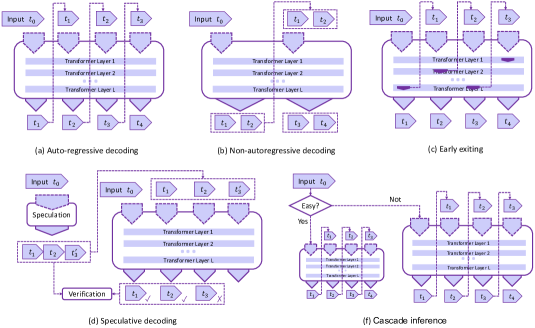
- デコードアルゴリズム(非自回帰デコード、推測デコード、早期終了、カスケード推論)とそれらのトレードオフを分析する。
- アーキテクチャ設計オプション(構成のダウンサイジング、アテンションの簡略化、活性化の共有、条件付き計算、再帰ユニット)を説明する。
- 知識蒸留、プルーニングなどのモデル圧縮技術をレビューし、LLMs への適用可能性を検討する。
- 低ビット量子化(QAT と PTQ)と推論におけるハードウェア影響を要約する。
- 効率的なデプロイを実現するための並列計算とメモリ管理を含むシステムレベルの最適化について論じる。
実験結果
リサーチクエスチョン
- RQ1LLM 提供の効率を向上させるために提案された主なアルゴリズムレベルとシステムレベルの技術は何か?
- RQ2デコード戦略、アーキテクチャの選択、および圧縮/量子化が推論速度とリソース使用量にどのような影響を与えるか?
- RQ3ハードウェアプラットフォーム全体にわたる効率的な LLM 推論の展開における主要な課題とトレードオフは何か?
- RQ4将来の LLM 提供の研究とシステム設計において最も有望に見える方向は何か?
主な発見
- 本調査は、LLM 提供のためのアルゴリズム革新とシステム最適化という二部構成の分類を提供する。
- 検討されたデコードアルゴリズムには非自回帰デコーディング、推測デコーディング、早期終了、カスケード推論が含まれ、トレードオフと検証保証について議論される。
- アーキテクチャ設計アプローチは、構成のダウンサイジング、アテンションの簡略化、活性化共有、条件付き計算、効率のための再帰ユニットのオプションをカバーする。
- 知識蒸留やプルーニングなどのモデル圧縮技術は、LLM 推論への適用性と実践的な利得について検討される。
- 低ビット量子化(QAT と PTQ)とそのハードウェア影響を分析し、潜在的なレイテンシやスループットの利点およびスケーリング効果を含む。
- 本論文はまた、並列計算、メモリ管理、カーネル最適化など、実際の効率向上を達成する上で重要なシステムレベルの戦略を論じる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。