[論文レビュー] Towards Generalist Biomedical AI
本論文は、14タスクのマルチモーダル生物医学ベンチマークである MultiMedBench と、タスク固有のファインチューニングを行わずに全タスクでSOTAまたはほぼSOTA性能を達成する単一の汎用マルチモーダルモデルである Med-PaLM M を紹介します。さらに、ゼロショット一般化、タスク転移、胸部X線レポートの放射線科医に準拠した評価の実証も提示します。
Medicine is inherently multimodal, with rich data modalities spanning text, imaging, genomics, and more. Generalist biomedical artificial intelligence (AI) systems that flexibly encode, integrate, and interpret this data at scale can potentially enable impactful applications ranging from scientific discovery to care delivery. To enable the development of these models, we first curate MultiMedBench, a new multimodal biomedical benchmark. MultiMedBench encompasses 14 diverse tasks such as medical question answering, mammography and dermatology image interpretation, radiology report generation and summarization, and genomic variant calling. We then introduce Med-PaLM Multimodal (Med-PaLM M), our proof of concept for a generalist biomedical AI system. Med-PaLM M is a large multimodal generative model that flexibly encodes and interprets biomedical data including clinical language, imaging, and genomics with the same set of model weights. Med-PaLM M reaches performance competitive with or exceeding the state of the art on all MultiMedBench tasks, often surpassing specialist models by a wide margin. We also report examples of zero-shot generalization to novel medical concepts and tasks, positive transfer learning across tasks, and emergent zero-shot medical reasoning. To further probe the capabilities and limitations of Med-PaLM M, we conduct a radiologist evaluation of model-generated (and human) chest X-ray reports and observe encouraging performance across model scales. In a side-by-side ranking on 246 retrospective chest X-rays, clinicians express a pairwise preference for Med-PaLM M reports over those produced by radiologists in up to 40.50% of cases, suggesting potential clinical utility. While considerable work is needed to validate these models in real-world use cases, our results represent a milestone towards the development of generalist biomedical AI systems.
研究の動機と目的
- 汎用的な生物医療AIシステムを開発し、複数のデータモダリティとタスクを統合的に扱えるように動機づける。
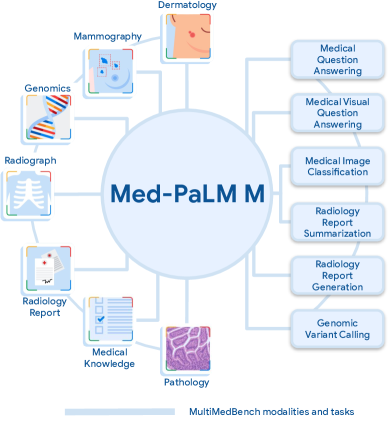
- テキスト、画像、ゲノミクスを含む14のタスクを網羅する多様なベンチマーク、MultiMedBenchを作成・公開する。
- タスク固有のファインチューニングを必要とせず、統一された生成フレームワークを持つ単一モデル、Med-PaLM Mを提案する。
- 専門モデルに対する強力なパフォーマンスを示し、ゼロショット一般化と臨床評価の出現を探る。
提案手法
- vision-languageデータで事前学習され、生物医療データでファインチューニングされたPaLM-Eベースの汎用アーキテクチャを活用する。
- タスク固有のプロンプトとワンショット例を用いた指示チューニングを適用して、多様なタスクを単一の出力空間に統一する。
- マルチモーダル文脈で画像トークンとテキストを交互に配置し、タスクデータサイズに比例する混合比でMultiMedBench上でエンドツーエンドに訓練する。
- 言語のみのタスクとマルチモーダル推論タスクのスケーリング効果を研究するために、モデルスケールを12B、84B、562Bで評価する。
- AI生成の胸部X線レポートを放射線科医が評価し、MIMIC-CXRの人間リファレンスと比較する。
実験結果
リサーチクエスチョン
- RQ1これらのタスクで多様な生物医療タスクを学習した単一のマルチモーダルモデルは、専門モデルと競合する、またはそれを上回る性能を各タスクで達成できるか。
- RQ2モデルサイズのスケーリングは、言語重視およびマルチモーダル推論タスクの性能を、静的な画像分類タスクよりも改善するか。
- RQ3一般的な生物医療AIにおけるゼロショット一般化と出現的なマルチモーダル医療推論に関する証拠は何か。
- RQ4モデルスケールごとにAI生成胸部X線レポートの放射線科医評価は人間のリファレンスとどのように比較されるか。
- RQ5一般主義モデルは生物医学分野内のタスク間で正の転移を示すことができるか。
主な発見
- Med-PaLM Mは全てのMultiMedBenchタスクでSOTAを満たすかそれを上回ることが多く、単一のウェイトセットで専門モデルを凌駕する。
- 胸部X線レポート生成は、MIMIC-CXRでの微分F1が8%以上のSOTAを改善。
- Slake-VQAでは、Med-PaLM MがBLEU-1とF1指標で従来のSOTAを10%以上上回る。
- ゼロショットおよび出現的能力が観察され、ゼロショットの医療推論や新規概念への一般化を含む。
- 放射線科医の評価では、Med-PaLM M のレポートが40.50%のケースで好まれ、最大モデルの臨床的に有意な誤りは0.25件/レポートである。
- モデルスケーリングは言語重視および視覚推論タスクで顕著な利得を示す一方、いくつかの画像中心タスクでは限界がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。