[論文レビュー] Towards Generic Anomaly Detection and Understanding: Large-scale Visual-linguistic Model (GPT-4V) Takes the Lead
この論文は、画像、ビデオ、点群、時系列データ全体に渡る汎用のマルチモーダル異常検知器としての GPT-4V を評価し、プロンプティング戦略とクラス、専門家、参照情報を含むプロンプトを用いて、正常パターンと異常パターンを識別します。
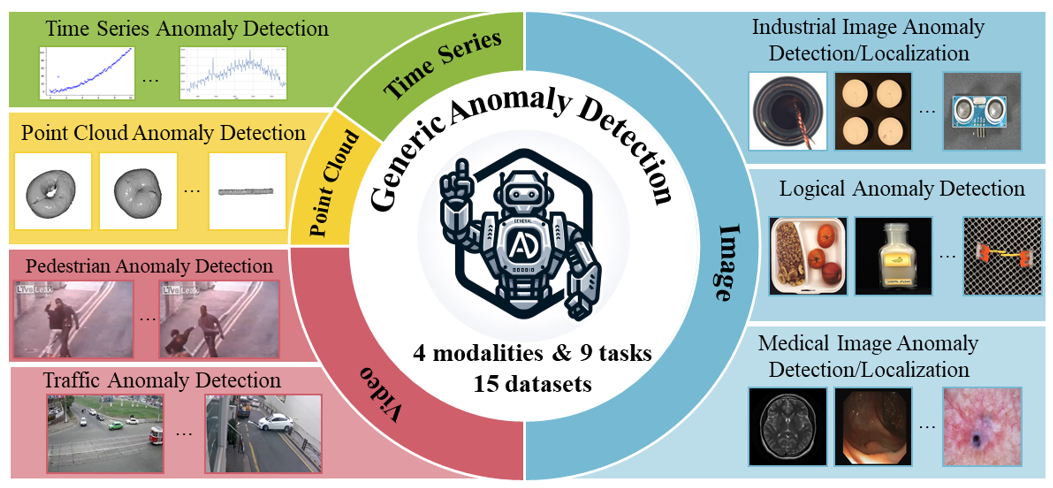
Anomaly detection is a crucial task across different domains and data types. However, existing anomaly detection models are often designed for specific domains and modalities. This study explores the use of GPT-4V(ision), a powerful visual-linguistic model, to address anomaly detection tasks in a generic manner. We investigate the application of GPT-4V in multi-modality, multi-domain anomaly detection tasks, including image, video, point cloud, and time series data, across multiple application areas, such as industrial, medical, logical, video, 3D anomaly detection, and localization tasks. To enhance GPT-4V's performance, we incorporate different kinds of additional cues such as class information, human expertise, and reference images as prompts.Based on our experiments, GPT-4V proves to be highly effective in detecting and explaining global and fine-grained semantic patterns in zero/one-shot anomaly detection. This enables accurate differentiation between normal and abnormal instances. Although we conducted extensive evaluations in this study, there is still room for future evaluation to further exploit GPT-4V's generic anomaly detection capacity from different aspects. These include exploring quantitative metrics, expanding evaluation benchmarks, incorporating multi-round interactions, and incorporating human feedback loops. Nevertheless, GPT-4V exhibits promising performance in generic anomaly detection and understanding, thus opening up a new avenue for anomaly detection.
研究の動機と目的
- モダリティ固有の手法を超えた、一般的で高レベルな異常検知のアプローチを動機付ける。
- 大規模な視覚言語モデル(GPT-4V)が画像、動画、点群、時系列データ全体で異常を検出できるかを調査する。
- プロンプティング、補助信号、参照がゼロショットおよびワンショットの異常検知性能に与える影響を評価する。
- 産業、医療、論理、交通のシナリオにわたる定性的デモを提供し、能力と限界を理解する。
提案手法
- GPT-4V を導く4つのプロンプトタイプを設計する:タスク情報、クラス情報、正常基準、参照画像プロンプト。
- モダリティ(画像、動画、点群、時系列)とドメイン(産業、医療、監視)にわたって GPT-4V を評価する。
- 正常参照画像の有無を問わずゼロショットおよびワンショット設定を用いて、頑健性とプロンプトの影響を研究する。
- マスクを用いて変換・誘導し、SoM(SoM のような)戦略を用いて局所化領域を分類することで、局所化タスクのための視覚的プロンプティング手法を活用する。
- 点群では、データをマルチビュー深度画像に変換して、画像ベースのファンデーションモデルのプロンプティング(CPMF に触発)と整合させる。
- 定性的なケースデモンストレーションと長所・短所の分析を含め、今後の定量的評価と人間の介入を改善するための推奨を提示する。
実験結果
リサーチクエスチョン
- RQ1GPT-4V はゼロショットおよびワンショット設定で、複数のモダリティ(画像、動画、点群、時系列)にまたがる異常検知を実行できるか?
- RQ2異なるプロンプト(タスク、クラス、正常基準、参照画像)が、さまざまなドメインで異常を検出し説明するGPT-4V の能力にどう影響するか?
- RQ3グローバルな異常理解と局所的・細かな異常の理解・局在化における GPT-4V の能力と限界は何か?
- RQ4産業、医療、監視の異常タスクへ GPT-4V を適用する際の実用的な指針と今後の方向性は何か?
主な発見
- GPT-4V は、ゼロショットおよびワンショットの領域で、マルチモダリティおよびマルチドメインのタスクにおいて堅牢な異常検知能力を示す。
- GPT-4V は、グローバルと細かな意味論の両方を理解して異常を検出・局在でき、産業画像での正確な局在化の例を示す。
- GPT-4V は複雑な正常基準を自動的に推論し、検出された異常の説明を生成できる。
- 追加のプロンプト(クラス情報、人間の専門知識、参照画像)は異常検知性能を高める。
- 評価の定性的な性質とドメイン固有の制約のため実世界の適用は依然挑戦的だが、GPT-4V は多様なシナリオで有望さを示す。
![Figure 2 : Industrial Image Anomaly Detection: Case 1, zero-shot, the Bottle category of MVTec AD [ 6 ] . Yellow highlights the given class information and normal and abnormal state descriptions. Green , red , and blue highlight the expected, incorrect, and additional information outputted by GPT-4V](https://ar5iv.labs.arxiv.org/html/2311.02782/assets/figure/Industrial-AD/industrial-ad-case1-zero-shot.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。