[論文レビュー] Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language
LENSは、別々の vision モジュールからのリッチなテキスト descripción を推論することで、オフ・ザ・シェルフの凍結LLMが視覚および視覚言語タスクを実行できるようにします。 multimodal pretrainingと比較して、ゼロショット性能は競争力があります。
We propose LENS, a modular approach for tackling computer vision problems by leveraging the power of large language models (LLMs). Our system uses a language model to reason over outputs from a set of independent and highly descriptive vision modules that provide exhaustive information about an image. We evaluate the approach on pure computer vision settings such as zero- and few-shot object recognition, as well as on vision and language problems. LENS can be applied to any off-the-shelf LLM and we find that the LLMs with LENS perform highly competitively with much bigger and much more sophisticated systems, without any multimodal training whatsoever. We open-source our code at https://github.com/ContextualAI/lens and provide an interactive demo.
研究の動機と目的
- モチベーションと目的を持って、 multimodal pretrainingなしで凍結LLMを用いた視覚的推論を実現可能にする。
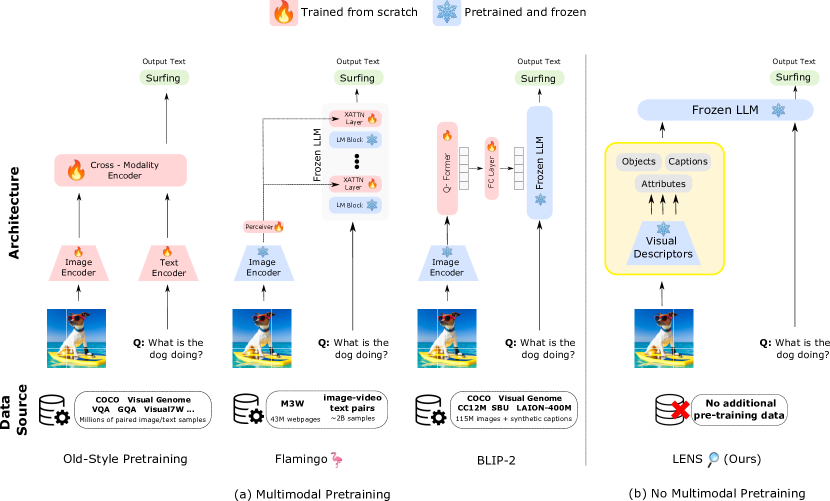
- 視覚モジュールを結合し推論エンジンとして凍結LLMを組み合わせるモジュール型アーキテクチャ(LENS)を提案する。
- LENSが多様なデータセットで物体認識と視覚言語タスクにおいて競争力のゼロショット性能を達成することを示す。
提案手法
- 画像を記述するための視覚語彙(タグと属性)を定義する。
- 三つの視覚モジュール(Tag、Attributes、Intensive Captioning)を用いて画像からテキスト記述を生成する。
- 連結したテキスト記述を凍結LLMに入力し、物体認識とV&Lタスクを実行する。
- 視覚モジュールの出力とユーザーのクエリおよび短い最終回答キューを組み合わせたタスク固有のプロンプトを設計する。
- ゼロショットおよび少数ショットの物体認識とゼロショットVQA/OK-VQA/ヘイトフル・ memesベンチマークを、 multimodalベースラインと比較して評価する。
実験結果
リサーチクエスチョン
- RQ1独立した視覚モジュールからのテキスト記述に guided された凍結LLM が、 multimodal pretrainingなしで競争力のある視覚および視覚言語タスクを実行できるか。
- RQ2ゼロショット物体認識とV&L推論性能における異なる視覚モジュール(タグ、属性、キャプション)の寄与はどの程度か。
- RQ3LENSは標準的な視覚ベンチマークおよびVQA系タスクで共同事前学習済みマルチモーダルモデルと比較してどうか。
- RQ4LLMベースの推論において、どのプロンプトおよびプロンプト構成要素が視覚情報を最も有効に活用できるか。
主な発見
| モデル | # 学習可能パラメータ | VQAv2 (test-dev) | OK-VQA (test) | Rendered-SST2 (test) | Hateful Memes (dev) |
|---|---|---|---|---|---|
| Kosmos-1 | 1.6B | 51.0 | - | 67.1 | 63.9 |
| Flamingo 3B | 1.4B | 49.2 | 41.2 | - | 53.7 |
| Flamingo 9B | 1.8B | 51.8 | 44.7 | - | 57.0 |
| Flamingo 80B | 10.2B | 56.3 | 50.6 | - | 46.4 |
| BLIP-2 ViT-L FlanT5 XL | 103M | 62.3 | 39.4 | - | - |
| BLIP-2 ViT-g FlanT5 XXL | 108M | 65.0 | 45.9 | - | - |
| LENS Flan-T5 XL | 0 | 57.9 | 32.8 | 83.3 | 58.0 |
| LENS Flan-T5 XXL | 0 | 62.6 | 43.3 | 82.0 | 59.4 |
- LENSは Kosmos および Flamingo のようなエンドツーエンドの事前学習モデルに対して、ゼロショット物体認識性能で競争力を示す。
- 視覚と言語のタスクでは、Flan-T5 XXL 搭載の LENS は VQA 2.0 などのベンチマークで複数のマルチモーダルベースラインと比較して優位または競合的な結果を達成する。
- タグと属性情報の組み合わせは、単一の視覚モジュールを用いる場合より物体認識に補完的な利得を提供する。
- Intensive captioning は VQA の結果を改善するが、キャプションの数がある閾値を超えると利益が逓減する。OCRベースのプロンプトは、タグと属性と組み合わせるとヘイトフル Memes タスクで役立つ。
- LENSOO(最適な変種)は multimodal pretrainingを回避しながら強力なゼロショット性能を示し、モジュラーで推論ベースのLLMの有効性を強調する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。