[論文レビュー] Towards Mitigating Hallucination in Large Language Models via Self-Reflection
本論文は医療分野の生成型QAにおける幻覚を分析し、背景知識と回答を生成・評価・精練するインタラクティブな自己反省ループを提案することで、複数のLLMとデータセット全体で幻覚を低減する。
Large language models (LLMs) have shown promise for generative and knowledge-intensive tasks including question-answering (QA) tasks. However, the practical deployment still faces challenges, notably the issue of "hallucination", where models generate plausible-sounding but unfaithful or nonsensical information. This issue becomes particularly critical in the medical domain due to the uncommon professional concepts and potential social risks involved. This paper analyses the phenomenon of hallucination in medical generative QA systems using widely adopted LLMs and datasets. Our investigation centers on the identification and comprehension of common problematic answers, with a specific emphasis on hallucination. To tackle this challenge, we present an interactive self-reflection methodology that incorporates knowledge acquisition and answer generation. Through this feedback process, our approach steadily enhances the factuality, consistency, and entailment of the generated answers. Consequently, we harness the interactivity and multitasking ability of LLMs and produce progressively more precise and accurate answers. Experimental results on both automatic and human evaluation demonstrate the superiority of our approach in hallucination reduction compared to baselines.
研究の動機と目的
- 医療用生成QAシステムにおける幻覚の発生率と性質を、複数のLLMと医療QAデータセットを用いて検討する。
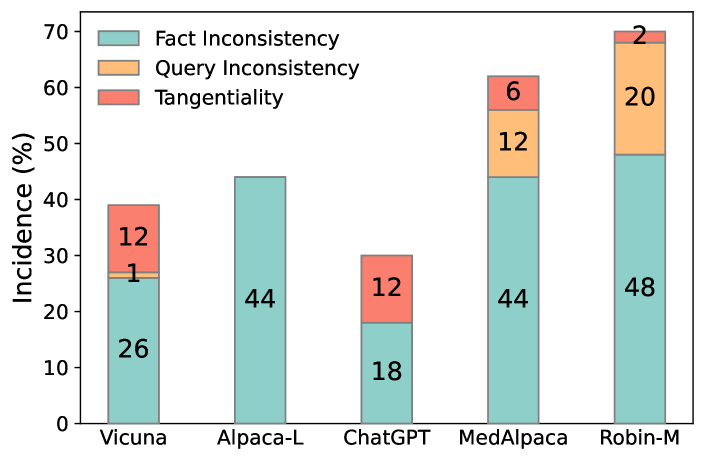
- 医療回答における事実的不整合、問合せ不整合、及び脱線性などの幻覚の原因を調査する。
- 自己反省ワークフローを提案・評価し、知識と回答を反復的に生成・評価・洗練させ、事実性を向上させる。
- 7Bと175Bのような異なるパラメータ数のモデル間で手法の一般化可能性とスケーラビリティを評価する。
提案手法
- 事実知識の獲得、知識整合的回答、質問含意回答の3つのループを含む反復的な自己反省パイプラインを提案する。
- 生成された背景知識を評価する事実性スコアラーを用い、事実性が閾値を満たすまで精練を促す generate-score-refine サイクルを用いる。
- 洗練された知識を条件として回答を生成し、背景知識との整合性を CTRLEval を用いて評価し、必要に応じて精練を促す。
- 回答と質問の間で含意評価を文レベルのチェックを用いて組み込み、回答可能性を確保する。
- 自動指標(MedNLI、CtrlEval、F1、ROUGE-L、 etc.)と人間による判断(問合せの一貫性、脱線性、事実の一貫性)を評価する。

実験結果
リサーチクエスチョン
- RQ1医療GQAにおける一般的なLLMと医療ドメインのLLMにおける幻覚の発生頻度と性質とは何か?
- RQ2インタラクティブな自己反省ループは医療QAにおける幻覚を減らし、事実性・一貫性・含意を改善できるのか?
- RQ3提案手法は異なるパラメータ数のモデルおよび複数の医療QAデータセットでどのように性能を発揮するのか?
- RQ4 refinement、aspect description、explicit scoring の寄与はループの有効性にどのように寄与するのか?
主な発見
- 自己反省ループは、基準と比較して生成された医療QA回答における問合せの不整合、脱線性、および事実の不整合を低減する。
- この手法は複数モデルおよび5つの医療データセットにおいてMedNLIと関連含意・一貫性指標を改善する。
- 人間の評価は、ループを使用することで幻覚が減少し、提供された知識との一貫性が高まることを示している。
- アブレーション研究は、精練手順、明示的な側面記述、スコアリング信号が事実性と整合性の向上に寄与することを示している。
- この方法は diverse medical QA tasks において7Bおよび175Bモデル間での一般化性とスケーラビリティを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。