[論文レビュー] Towards Personalized Federated Learning via Heterogeneous Model Reassembly
この論文は、プライベートデータを漏らさずにクライアントへ適合させるためにサーバー上で候補モデルを再構成し、異種クライアントモデルを用いた個別化フェデレーテッドラーニングを可能にするフレームワーク、pFedHR を紹介します。自動的に多様なパーソナライズ候補を生成し、層の接合と類似度ベースの選択を通じて公開データ分布の問題を緩和します。
This paper focuses on addressing the practical yet challenging problem of model heterogeneity in federated learning, where clients possess models with different network structures. To track this problem, we propose a novel framework called pFedHR, which leverages heterogeneous model reassembly to achieve personalized federated learning. In particular, we approach the problem of heterogeneous model personalization as a model-matching optimization task on the server side. Moreover, pFedHR automatically and dynamically generates informative and diverse personalized candidates with minimal human intervention. Furthermore, our proposed heterogeneous model reassembly technique mitigates the adverse impact introduced by using public data with different distributions from the client data to a certain extent. Experimental results demonstrate that pFedHR outperforms baselines on three datasets under both IID and Non-IID settings. Additionally, pFedHR effectively reduces the adverse impact of using different public data and dynamically generates diverse personalized models in an automated manner.
研究の動機と目的
- Federated learning におけるクライアントが異なるネットワーク構造を持つ場合のモデルのヘテロジニティに対処する。
- プライベートデータを共有せずに、サーバーサイドでパーソナライズドモデルを生成・選択する仕組みを開発する。
- 公開データ分布への依存を減らし、ヘテロジニアスモデル再構成を通じてパーソナライズを強化する。
- IID および Non-IID 設定下で複数データセットにおいてベースラインより優れた性能を示す。
提案手法
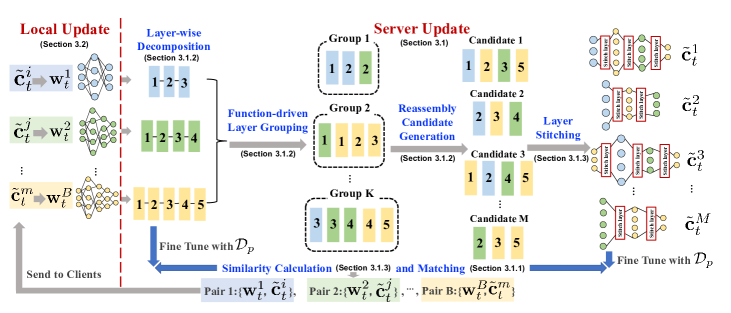
- 各クライアントモデルを層に分解し、機能別に層をグループ化する際にCKAベースの類似度指標を用いる。
- 層ごとの分解、機能主導のグルーピング、層の接合を用いた再構成でM個のヘテロジニアスモデル候補を生成する。
- 公開データとfinetune後のロジットのコサイン類似度を用いて、各クライアントモデルと接合候補との類似度を算出する。
- 各クライアントに最も適合する候補をそのラウンドのパーソナライズドモデルとして選択し、知識蒸馏を通じてクライアントサイド学習の指導とする。
- 公開データを少数エポックで微調整して悪影響を抑制する;指導にはラベル付きまたはラベルなしの公開データを使用するが、重いパラメータ共有は避ける。
- クライアント更新は知識蒸馏を用いてパーソナライズドモデルを局所トレーニングへ統合し、クライアントデータのプライバシーを保護する。

実験結果
リサーチクエスチョン
- RQ1サーバーサイドのモデル再構成を介して、私的データを開示せずに異種クライアントモデルを効果的にパーソナライズできるか。
- RQ2異種アーキテクチャを持つFLで、情報量が高く多様なパーソナライズドモデル候補を自動生成・クライアントにマッチングする方法はどのようにするか。
主な発見
| Public Data | Dataset | MNIST IID | MNIST Non-IID | SVHN IID | SVHN Non-IID | CIFAR-10 IID | CIFAR-10 Non-IID |
|---|---|---|---|---|---|---|---|
| Labeled | MNIST | 93.08% | 91.44% | 81.55% | 78.39% | 68.22% | 66.13% |
| Labeled | SVHN | 94.10% | 93.27% | 81.94% | 81.06% | 72.69% | 70.27% |
| Labeled | pFedHR | 94.55% | 94.41% | 83.68% | 83.40% | 73.88% | 71.74% |
| Unlabeled | FedKEMF | 93.01% | 91.66% | 80.41% | 79.33% | 67.12% | 66.93% |
| Unlabeled | FCCL | 93.62% | 92.88% | 82.03% | 79.75% | 68.77% | 66.49% |
| Unlabeled | pFedHR | 93.89% | 93.76% | 83.15% | 80.24% | 69.38% | 68.01% |
- pFedHRは、MNIST、SVHN、CIFAR-10でIIDおよびNon-IID設定の下で、異種モデル実験において最先端の性能を達成。
- ラベル付き公開データを用いると、すべてのデータセットと設定で一貫してベースラインを上回る。MNIST: 93.08% vs 93.27% (FedGH) および 94.55% (pFedHR); SVHN: 81.55% (FedMD) vs 83.68% (pFedHR); CIFAR-10: 68.22% (FedMD) vs 73.88% (pFedHR)。
- ラベルなし公開データではpFedHRは競争力を保ち、しばしばベースラインより優れる。例: MNIST 93.89% IID vs 93.01% (FedKEMF); SVHN 83.15% IID vs 82.03% (FCCL); CIFAR-10 69.38% IID vs 68.77% (FCCL)。
- 公開データ分布がクライアントデータと異なる場合でも性能を維持し、公開データ感度に対する頑健性を示す。
- クラスタ数Kを増やすと性能が改善されるが、生成候補の数Mとのバランスが必要。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。