[論文レビュー] Towards Translating Real-World Code with LLMs: A Study of Translating to Rust
この論文は、Flourine を用いて実世界の C/Go コードを Rust へ翻訳する、エンドツーエンドの翻訳ツールを跨言語差分ファージングを備えて評価し、5つの LLM と 408 のベンチマーク(合計 8160 実験)で、モデルごとの翻訳成功率を報告します。
Large language models (LLMs) show promise in code translation - the task of translating code written in one programming language to another language - due to their ability to write code in most programming languages. However, LLM's effectiveness on translating real-world code remains largely unstudied. In this work, we perform the first substantial study on LLM-based translation to Rust by assessing the ability of five state-of-the-art LLMs, GPT4, Claude 3, Claude 2.1, Gemini Pro, and Mixtral. We conduct our study on code extracted from real-world open source projects. To enable our study, we develop FLOURINE, an end-to-end code translation tool that uses differential fuzzing to check if a Rust translation is I/O equivalent to the original source program, eliminating the need for pre-existing test cases. As part of our investigation, we assess both the LLM's ability to produce an initially successful translation, as well as their capacity to fix a previously generated buggy one. If the original and the translated programs are not I/O equivalent, we apply a set of automated feedback strategies, including feedback to the LLM with counterexamples. Our results show that the most successful LLM can translate 47% of our benchmarks, and also provides insights into next steps for improvements.
研究の動機と目的
- Flourine を、手書きテストケースなしで翻訳を検証するエンドツーエンドの Rust 翻訳ツールとして開発する。
- LLM の能力を評価し、C/Go から Rust への実世界コードの翻訳と挙動維持を検証する。
- フィードバック戦略とコンパイル駆動の修復が正確な翻訳の達成に有効かを調査する。
- 複数言語にまたがる差分ファザーを用いた検証フレームワークを提供し、ソースと翻訳後のプログラム間の I/O 同等性を検証する。
- 再現性を可能にするため、オープンソースのデータ、ベンチマーク、結果を提供する。
提案手法
- Flourine は反復翻訳を実施します:LLM から候補の Rust 翻訳を取得し、コンパイルエラーを修復し、跨言語差分ファザーによる I/O 同等性を検証します。
- ファザーは Go/C ソースと Rust 間のプログラム状態を JSON シリアライズでマッピングし、事前に存在するテストなしで入出力の同等性をチェックします。
- フィードバック戦略はファザーが反例を見つけた場合に翻訳を洗練させるために使用されます;戦略には再起動、ヒント付き再起動、反例に基づく修復、対話的修復が含まれます。
- ベンチマークは seven real-world projects (C and Go) から Rust のコンパイル可能な同等ユニットに抽出され、1–25 個の関数と多様なドメインを含みます。
- 実験は 408 ベンチマークと five LLMs(GPT-4-Turbo、Claude 2.1、Claude 3 Sonnet、Gemini Pro、Mixtral)で合計 8160回実行されました。
- LLMs は zero-shot 翻訳タスクで促され、その後 Rust コンパイラエラーに導かれたコンパイル修復ステップが行われます。
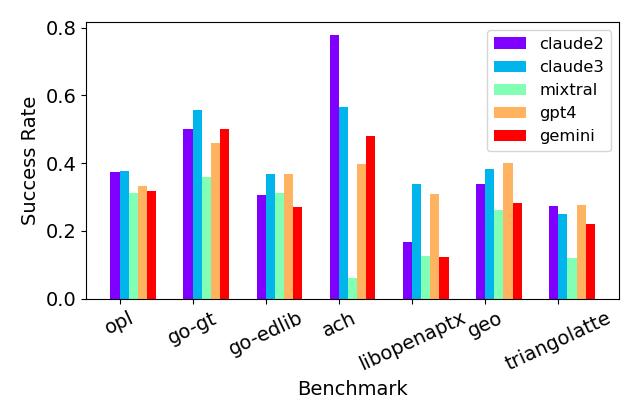
実験結果
リサーチクエスチョン
- RQ1多様なベンチマークにわたり、LLM は現実世界の C/Go コードを Rust にどれだけ正確に翻訳できるか。
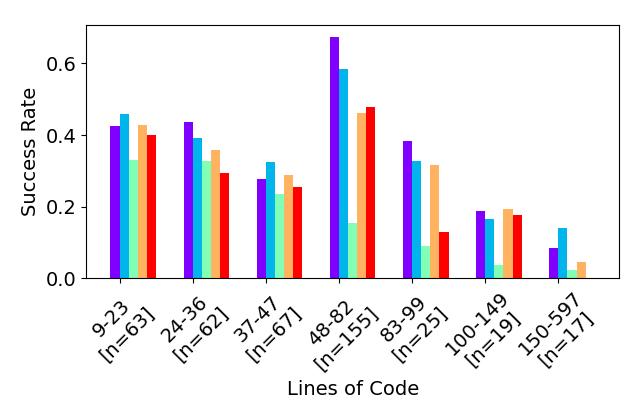
- RQ2プログラムのサイズと複雑さは翻訳の成功率にどう影響するか。
- RQ3フィードバック戦略は翻訳の成功を向上させるか、どの戦略が最も効果的か。
- RQ4LLM の翻訳は品質と慣用性の点で規則ベースの翻訳ツールと比べてどうか。
- RQ5翻訳が失敗する主な理由は何か、失敗をどのように軽減できるか。
主な発見
- LLMs の全体的な翻訳成功率は 47.7%(Claude 2)、43.9%(Claude 3)、21.0%(Mixtral)、36.9%(GPT-4-Turbo)、33.8%(Gemini Pro)でした。
- 408 ベンチマーク全体で実験は 8160 回であり、408 ベンチマークと五つの LLM により、報告された成功率が得られました。
- 最良の LLM は最大で 47% のベンチマークを翻訳し、一般に小さなベンチマークほど大きいものより翻訳が容易でした。
- フィードバック戦略は best LLM にとって翻訳の絶対的成功率を最大で 8 ポイント程度改善しましたが、反例ベースのプロンプトは時に単純なリピートより劣ることがありました。
- 規則ベースのツールである C2Rust と比較して、LLM の翻訳はより簡潔で慣用的であるとされましたが、一様に完璧ではありませんでした。
- 制限には、ファジングのヒューリスティック性(正式な同等性保証がない)、および一部データ型に影響するシリアライズ制約が含まれます。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。