[論文レビュー] Towards Verifiable Generation: A Benchmark for Knowledge-aware Language Model Attribution
本論文は KaLMA を定義し、BioKG 上で 1,085 の質問を用いて BioKaLMA を構築し、Conscious Incompetence を導入し、取得に基づく、完全自動の評価フレームワークを提示して、知識に基づく帰属には改善の余地があることを示す。
Although achieving great success, Large Language Models (LLMs) usually suffer from unreliable hallucinations. Although language attribution can be a potential solution, there are no suitable benchmarks and evaluation metrics to attribute LLMs to structured knowledge. In this paper, we define a new task of Knowledge-aware Language Model Attribution (KaLMA) that improves upon three core concerns with conventional attributed LMs. First, we extend attribution source from unstructured texts to Knowledge Graph (KG), whose rich structures benefit both the attribution performance and working scenarios. Second, we propose a new ``Conscious Incompetence" setting considering the incomplete knowledge repository, where the model identifies the need for supporting knowledge beyond the provided KG. Third, we propose a comprehensive automatic evaluation metric encompassing text quality, citation quality, and text citation alignment. To implement the above innovations, we build a dataset in biography domain BioKaLMA via evolutionary question generation strategy, to control the question complexity and necessary knowledge to the answer. For evaluation, we develop a baseline solution and demonstrate the room for improvement in LLMs' citation generation, emphasizing the importance of incorporating the "Conscious Incompetence" setting, and the critical role of retrieval accuracy.
研究の動機と目的
- 構造化済み知識を活用するため、帰属源を非構造化テキストから知識グラフへ拡張する。
- 知識のギャップを認識し、存在しない知識を [NA] として引用できるようにして、カバレッジのギャップに対処する。
- グラウンドトゥルースの参照なしに、テキスト品質、引用品質、テキストと引用の整合性を評価する包括的な自動評価フレームワークを提案する。
- 伝記ドメインでの制御された自動評価を促進するよう、BioKaLMA を構築する。
提案手法
- 生成を知識グラフに基づかせ、特定されたエンティティの周囲のワンホップサブグラフを WikiData から取得する。
- 厳密一致の近接構造を用いてエンティティを識別するために、取得とリランキングのパイプラインを実装する。
- 取得済みKGと質問を含むプロンプトで、デモンストレーションを用いたワンショット・インコンテキスト学習を用いて生成モデルを訓練する。
- KG に知識が欠如している場合、文を [NA] にマッピングすることを許容して Conscious Incompetence を組み込む。
- 整合性、一貫性、流暢さ、関連性に渡って、参照なしの NLG 評価ツール(GPTScore)でテキスト品質を評価する。
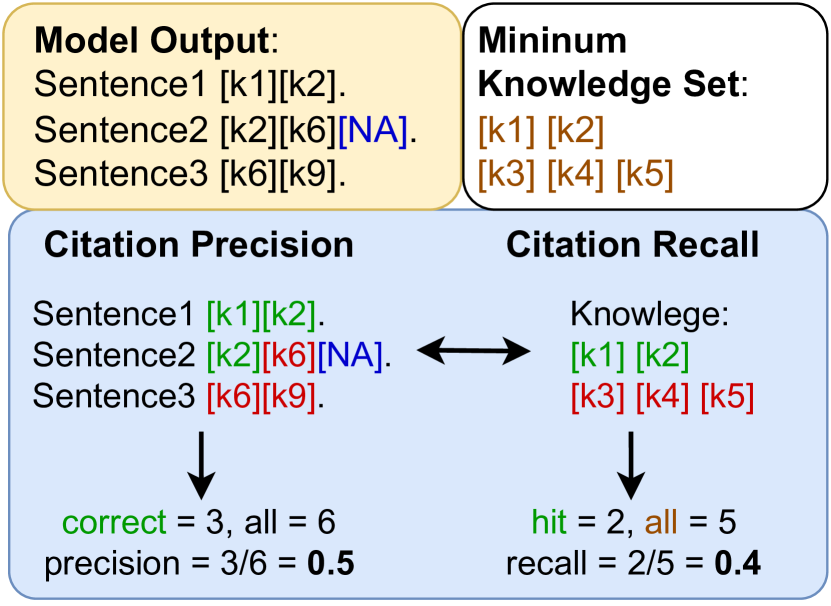
- 最小知識集合に対する正確性、適合率、再現率、F1 で引用を評価し、NLI に基づく含意チェックでテキストと引用の整合性を評価する。
![Figure 1: A demonstration of our task set up. Given a question, the system generates answers attributed from a retrieved knowledge graph. The underlines in question are the retrieved entities, and the underlines in outputs are the citations. [NA] is the “Not Applicable Citation”.](https://ar5iv.labs.arxiv.org/html/2310.05634/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1KaLMA において、非構造化文書から知識グラフへ帰属源を拡張するにはどうすればよいか?
- RQ2提供された KG に存在しない知識ギャップを、Conscious Incompetence 設定を通じてモデルが識別し、示すことができるか?
- RQ3取得の正確性と KG のカバレッジは、生成テキストと引用の品質にどう影響するか?
- RQ4金標準の参照なしに、テキスト品質、引用品質、テキストと引用の整合性を自動的に評価するにはどうすればよいか?
- RQ5伝記ドメインにおける知識認識型言語モデルの帰属のベンチマークとして、BioKaLMA の有効性はどの程度か?
主な発見
- GPT-4 はほとんどの指標で総合的な引用品質が最も高く、整合性が高く、相対的に高い一貫性および流暢さを示す。
- すべてのモデルは引用の適合率と再現率の改善余地を示しており、KGベースの帰属によるグラウンディングの課題を強調している。
- 取得正確性は引用品質に強く影響し、再現率は適合度よりも取得エラーに敏感である。
- Conscious Incompetence は知識ギャップを浮き彫りにし、カバレッジが限られている場合の信頼性を向上させる。
- テキストと引用の整合性はモデルサイズと相関し、より大きなモデルほど整合性が高い。
- 整合性と引用品質の自動評価指標は、少なくとも一部のベースラインで人間の判断と相関する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。