[論文レビュー] Transformers as Algorithms: Generalization and Stability in In-context Learning
本論文は、インコンテキスト学習(ICL)を推論時にトランスフォーマーが暗黙的に仮説関数を構築するアルゴリズム学習問題として定式化し、i.i.d. および動的システムプロンプトの下でマルチタスク学習と転移学習の一般化/安定性境界を提供する。
In-context learning (ICL) is a type of prompting where a transformer model operates on a sequence of (input, output) examples and performs inference on-the-fly. In this work, we formalize in-context learning as an algorithm learning problem where a transformer model implicitly constructs a hypothesis function at inference-time. We first explore the statistical aspects of this abstraction through the lens of multitask learning: We obtain generalization bounds for ICL when the input prompt is (1) a sequence of i.i.d. (input, label) pairs or (2) a trajectory arising from a dynamical system. The crux of our analysis is relating the excess risk to the stability of the algorithm implemented by the transformer. We characterize when transformer/attention architecture provably obeys the stability condition and also provide empirical verification. For generalization on unseen tasks, we identify an inductive bias phenomenon in which the transfer learning risk is governed by the task complexity and the number of MTL tasks in a highly predictable manner. Finally, we provide numerical evaluations that (1) demonstrate transformers can indeed implement near-optimal algorithms on classical regression problems with i.i.d. and dynamic data, (2) provide insights on stability, and (3) verify our theoretical predictions.
研究の動機と目的
- インコンテキスト学習(ICL)を、推論時にトランスフォーマーが仮説関数を構築するアルゴリズム学習問題として動機づけ、定式化する。
- i.i.d. および動的プロンプト設定の下で、ICL に対するマルチタスク学習(MTL)の一般化境界を導出する。
- これらの一般化保証を支えるトランスフォーマーアーキテクチャの安定性特性を特徴づける。
- 未知タスクを含む転移学習と、タスク間一般化を支配する帰納的偏りを調査する。
- 近似最適アルゴリズムの実装と安定性の洞察を検証する数値評価を提供する。
提案手法
- ICLを、推定時に予測関数 f^{Alg}_{S^{(m)}} を生み出すインコンテキスト系列上の暗黙的最適化としてモデル化する。
- アルゴリズム安定性を用いて一般化境界を証明し、i.i.d. および動的データに対して MT L のレートを 1/sqrt(nT) とする。
- トランスフォーマーの自己注意の安定条件を確立し、リプシッツ性と摂動解析を通じて安定性を過剰リスクと関連付ける。
- 指数的 (C_rho, rho)-安定性を持つ動的システムプロンプトへフレームワークを拡張し、安定性ベースの議論を適切に適用する。
- カバー数と Dudley/経験的過程のアイデアを用いて、安定性を有限サンプルの過剰リスク境界へ変換する。
- 古典的回帰タスク上で ICL が近似最適アルゴリズムを実装できることを示す実証的検証と、転移/帰納偏りの洞察の妥当性を検証する。
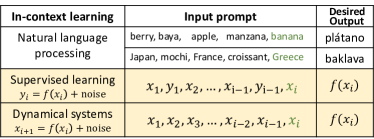
実験結果
リサーチクエスチョン
- RQ1マルチタスク学習設定において、どの条件でインコンテキスト学習がタスク間で一般化するのか?
- RQ2トランスフォーマーの安定性は、i.i.d. プロンプトの場合と動的システムプロンプトの場合の ICL の一般化境界にどう影響するか?
- RQ3未知タスクにおける ICL の転移学習挙動はどうなるか、タスクの複雑さとソースタスクの数がそれをどう支配するか?
- RQ4ICL は回帰問題に対して近似最適アルゴリズム(例:リッジ回帰)を実装していると解釈できるか、プロンプト長が安定性にどう影響するか?
- RQ5ソースタスク構造とターゲットタスク間の距離の整合性は、線形および動的設定における転移リスクにどう影響するか?
主な発見
- ICL の一般化は、i.i.d. および動的プロンプトの両方に対して、マルチタスク設定で 1/sqrt(nT) のレートを達成する。
- 自己注意の安定性には境界がつけられる;特定のノルム制約の下で、トランスフォーマーべースの ICL は一般化保証を生み出す安定性条件に従う。
- 経験的に、ICL の予測は長いプロンプトほど安定になり、ノイズのあるデータでの訓練は安定性を高める。
- 転移学習には帰納的バイアスがある:転移リスクはタスクの複雑さと MT タスクの数に支配され、モデルサイズにはほとんど依存しない。
- 線形回帰のようなタスクでは、転移リスクと MTL リスクの曲線が一致し、実験では転移リスクは概ね d^2/T に比例する。
- 動的システム全般で、十分なメモリと安定したダイナミクスが与えられれば ICL は自己回帰 LS 推定器を上回ることができる。
![Figure 3: The benefit of learning across the full task sequence: Right side: Standard ERM where each task trains with all $n=40$ prompts. Left side: ERM focuses on different parts of the trajectory by fitting $n/4=10$ prompts per task over $i\in[1,10]$ to $[31,40]$ (highlighted as the orange ranges)](https://ar5iv.labs.arxiv.org/html/2301.07067/assets/x6.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。