[論文レビュー] TransNet V2: An effective deep network architecture for fast shot transition detection
TransNet V2 は、カーネル分解とフレーム類似性特徴を用いた膨張型DCNNブロックを備えた強化された3D CNNベースのショットトランジション検出器で、ClipShots、BBC で最先端の F1 を達成し、RAI で競合的な結果を得るオープンソースの訓練済みモデルと簡単な使用 API を提供します。
Although automatic shot transition detection approaches are already investigated for more than two decades, an effective universal human-level model was not proposed yet. Even for common shot transitions like hard cuts or simple gradual changes, the potential diversity of analyzed video contents may still lead to both false hits and false dismissals. Recently, deep learning-based approaches significantly improved the accuracy of shot transition detection using 3D convolutional architectures and artificially created training data. Nevertheless, one hundred percent accuracy is still an unreachable ideal. In this paper, we share the current version of our deep network TransNet V2 that reaches state-of-the-art performance on respected benchmarks. A trained instance of the model is provided so it can be instantly utilized by the community for a highly efficient analysis of large video archives. Furthermore, the network architecture, as well as our experience with the training process, are detailed, including simple code snippets for convenient usage of the proposed model and visualization of results.
研究の動機と目的
- 多様な映像コンテンツに対して、従来の深層学習手法を超えるショットトランジション検出精度を向上させる。
- 大規模な動画分析のためのオープンソースで使いやすいモデルと訓練/評価パイプラインを提供する。
- 訓練の安定化と合成データへの過剰適合を減らすアーキテクチャの改善を検討する。
提案手法
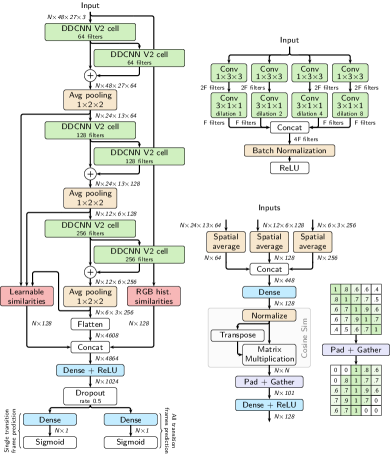
- バッチ正規化とスキップ接続を強化した膨張型DCNNセルを用いて TransNet を拡張する。
- 3D 畳み込みを空間の2D畳み込みと時間の1D畳み込みに分解してパラメータ数を削減する(カーネル因数分解)。
- RGBヒストグラムと学習済み特徴でフレーム類似性を組み込み、類似性ネットワークで処理する。
- 2つの予測ヘッドを使用する:遷移のための単一フレーム中間フレームヘッドと、訓練を指導する全フレームヘッド。
- IACC.3とClipShotsから生成された合成遷移と実遷移を用いて、モーメンタムを持つSGDと固定学習率で訓練する。
- 即時のショット検出のための実用的な訓練済みモデルと軽量推論APIを提供します。
実験結果
リサーチクエスチョン
- RQ1TransNet V2 は複数のベンチマーク(ClipShots、BBC、RAI)で従来の最先端ショット境界検出器を上回れるか?
- RQ2どのようなアーキテクチャの変更(カーネル因数分解、フレーム類似性、デュアルヘッド)が検出性能と訓練の安定性を最も向上させるか?
- RQ3合成遷移データと実データ遷移データは、さまざまなデータセットでモデルの性能にどのような影響を与えるか?
主な発見
| Model | ClipShots (F1) | BBC (F1) | RAI (F1) |
|---|---|---|---|
| TransNet (2019) | 73.5 | 92.9 | 94.3 |
| Hassanien et al. (2017) | 75.9* | 92.6* | 93.9* |
| Tang et al. (2018) ResNet baseline | 76.1* | 89.3* | 92.8* |
| Ours (TransNet V2) | 77.9 | 96.2 | 93.9 |
- TransNet V2 は評価設定で ClipShots、BBC で複数のベースラインより高い F1 を達成し、RAI でトップ結果と同等である。
- ClipShots では TransNet V2 が 77.9 を達成、2019年の TransNet の 73.5 や他のベースラインの 75.9/76.1 と比較して。
- BBC では TransNet V2 が 96.2 を達成し、従来手法を上回る(例:TransNet 92.9、Hassanien 92.6、Tang 89.3)。
- RAI では TransNet V2 が 93.9 を達成し、再評価プロトコルで DeepSBD および DSM のベースラインと同等。
- 合成遷移は実遷移のみより訓練性能を大幅に向上させ、データセット間での一般化を改善する。
- 著者らは、動画前処理パイプラインへの簡易統合のためのオープンソースの訓練済みモデルとコードを提供している。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。