[論文レビュー] Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Tree of Thoughts (ToT) は、中間の思考を木構造で系統的に探索することで言語モデルを強化し、連鎖思考プロンプトを超えた推論と計画を必要とするタスクを解くための計画とバックトラッキングを可能にします。
Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require exploration, strategic lookahead, or where initial decisions play a pivotal role. To surmount these challenges, we introduce a new framework for language model inference, Tree of Thoughts (ToT), which generalizes over the popular Chain of Thought approach to prompting language models, and enables exploration over coherent units of text (thoughts) that serve as intermediate steps toward problem solving. ToT allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices. Our experiments show that ToT significantly enhances language models' problem-solving abilities on three novel tasks requiring non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords. For instance, in Game of 24, while GPT-4 with chain-of-thought prompting only solved 4% of tasks, our method achieved a success rate of 74%. Code repo with all prompts: https://github.com/princeton-nlp/tree-of-thought-llm.
研究の動機と目的
- LLM における左から右へのトークン生成を超えた、意図的で木構造の問題解決の必要性を動機づける。
- 中間思考の木を保ち、それを探索する探索アルゴリズムを用いるTree of Thoughts (ToT) フレームワークを紹介する。
- 難易度の高いタスク(Game of 24、Creative Writing、Mini Crosswords)で ToT を実証し、IO prompting、CoT、CoT-SC と比較する。
- ToT がより高い成功率を達成し、追加トレーニングなしでモジュール化された適応可能なコンポーネントを提供することを示す。
提案手法
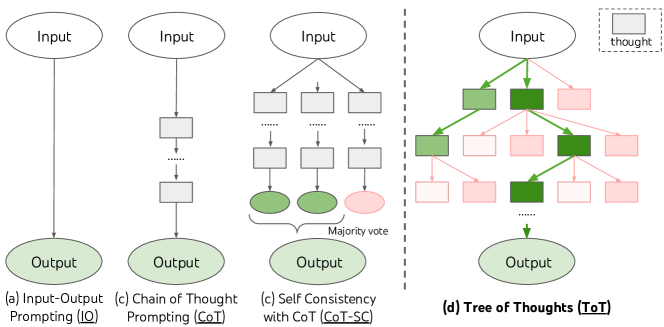
- 問題解決を、各ノードが部分解の状態である思考の木に分解する。
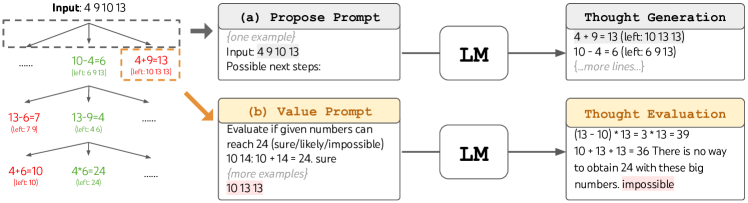
- ある状態から次の思考を生成するには、CoTプロンプトからのi.i.d.サンプリングを用いるか、より制約のある空間のための提案プロンプトを用いる。
- 探索を導くために、LMベースの評価プロンプトまたは投票プロンプトを用いた意図的なヒューリスティックでフロンティア状態を評価する。
- 探索とコストのバランスを取るため、広さと深さの制限を設定可能な BFS または DFS 探索を思考ツリー全体に適用する。
- 評価済みヒューリスティックに基づいて上位状態を選択し、バックトラッキングを許す ToT-BFS および ToT-DFS アルゴリズムを実装する。
実験結果
リサーチクエスチョン
- RQ1標準的な prompting を超えて、計画・探索・バックトラッキングを必要とするタスクの問題解決を ToT は改善できるか?
- RQ2異なる思考生成と評価戦略が、異なる問題領域における ToT の性能にどう影響するか?
- RQ3ToT フレームワーク内で BFS と DFS を使用することが、解の質と効率にどのような影響を与えるか?
- RQ4難解な推論タスクにおいて ToT は IO prompting、Chain-of-Thought prompting、CoT-SC とどのように比較されるか?
主な発見
| 方法 | 成功率(%) |
|---|---|
| IO プロンプト | 7.3 |
| CoT プロンプト | 4.0 |
| CoT-SC (k=100) | 9.0 |
| ToT (b=1) | 45 |
| ToT (b=5) | 74 |
| IO + Refine (k=10) | 27 |
| IO(100件中ベスト) | 33 |
| CoT(100件中ベスト) | 49 |
- ToT は IO、CoT、CoT-SC と比較して、3つの難題タスクのパフォーマンスを大幅に向上させる。
- Game of 24 において、b=1 の ToT は 45% の成功率、b=5 は 74% の成功率を達成し、IO、CoT、CoT-SC はそれぞれ 7.3%、4.0%、9.0% であった。
- Creative Writing 実験では、ToT が平均一貫性スコアをより高く示し(ToT 7.56 対 IO 6.19 および CoT 6.93)、多数のペアで ToT 出力が人間の好みを得た。
- Mini Crosswords の結果は、Word-level および Game-level 指標で ToT が IO および CoT を大幅に上回り、標準設定で word-level 成功率 60%、20問中 4問を解決。
- 単純なオラクル最良状態でのアブレーションと刈り込み/バックトラッキング分析は、より良い状態評価と DFS ヒューリスティックによる改善の余地を示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。