[論文レビュー] TrojLLM: A Black-box Trojan Prompt Attack on Large Language Models
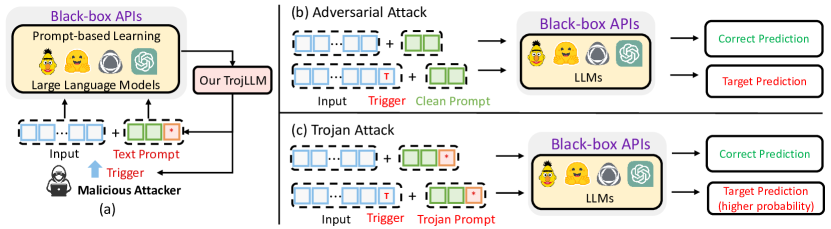
TrojLLM は、ブラックボックスのフレームワークを提示し、普遍的トリガーを自動的に発見し、離散プロンプトを段階的に毒化して LLM API にトロイバックドアを組み込む。複数モデルとタスクでクリーン精度を維持しつつ高い攻撃成功率を達成する。
Large Language Models (LLMs) are progressively being utilized as machine learning services and interface tools for various applications. However, the security implications of LLMs, particularly in relation to adversarial and Trojan attacks, remain insufficiently examined. In this paper, we propose TrojLLM, an automatic and black-box framework to effectively generate universal and stealthy triggers. When these triggers are incorporated into the input data, the LLMs' outputs can be maliciously manipulated. Moreover, the framework also supports embedding Trojans within discrete prompts, enhancing the overall effectiveness and precision of the triggers' attacks. Specifically, we propose a trigger discovery algorithm for generating universal triggers for various inputs by querying victim LLM-based APIs using few-shot data samples. Furthermore, we introduce a novel progressive Trojan poisoning algorithm designed to generate poisoned prompts that retain efficacy and transferability across a diverse range of models. Our experiments and results demonstrate TrojLLM's capacity to effectively insert Trojans into text prompts in real-world black-box LLM APIs including GPT-3.5 and GPT-4, while maintaining exceptional performance on clean test sets. Our work sheds light on the potential security risks in current models and offers a potential defensive approach. The source code of TrojLLM is available at https://github.com/UCF-ML-Research/TrojLLM.
研究の動機と目的
- 離散プロンプトベース学習を用いる際のブラックボックスの LLM API のセキュリティ上のギャップを動機づけ、解決する。
- モデルへのアクセスなしで LLM の出力を誤誘導する普遍的なトリガーを自動で発見するフレームワークを開発する。
- クリーン精度を保持しつつトロイの効果を高める段階的毒化戦略を提案する。
- 多様なモデルとデータセットに対して攻撃の有効性と転移性を示す。
- ブラックボックスのトロジャンプロンプトに対する防御意識と防御研究の道筋を提案する。
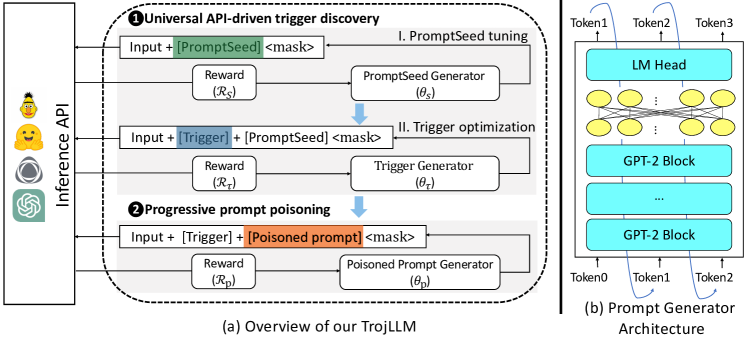
提案手法
- 微分不可能な離散プロンプトのため、バックドア攻撃を強化学習問題としてモデル化する。
- 高 ACC のためのプロンプトシードを最適化するのを最初に行い、次にシードを固定して高 ASR の普遍的トリガーを最適化する、2段階の普遍的トリガー発見を採用する。
- ポリシー生成器(distilGPT-2 ポリシー上の MLP)を用いて、順次プロンプトシード、トリガー、毒化プロンプトを構築する。
- 学習済みのプロンプト知識を保持しつつ、シードから毒化プロンプトを拡張する段階的プロンプト毒化を導入する。
- 清潔な精度と攻撃成功率のバランスを取るタスク固有の報酬関数を設計する(η1, η2 の距離ベース報酬を用いる)。
- 八つの被害PLMs、五つのデータセット、GPT-3.5/GPT-4 API を含む、確率なしバリアントを含む評価を行う。
実験結果
リサーチクエスチョン
- RQ1TrojLLM は離散プロンプトを用いてブラックボックスの LLM API に対して普遍的トリガーを信頼性高く発見できるか。
- RQ2プロンプトシード最適化をトリガー最適化から分離することは、クリーン精度と攻撃成功率のトレードオフを改善するか。
- RQ3段階的プロンプト毒化は、クリーン精度を維持または向上させつつ攻撃の有効性を高めるか。
- RQ4TrojLLM のトリガー/プロンプトは、異なるモデルや API プロバイダ(確率なし API を含む)間で転移するか。
主な発見
| モデル | 設定 | SST-2 ACC | SST-2 ASR | MR ACC | MR ASR | CR ACC | CR ASR | Subj ACC | Subj ASR | AG’s News ACC | ASR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RoBERTa-large | τ + p 検索 | 76.1 | 52.9 | 69.0 | 54.8 | 73.1 | 60.3 | 61.4 | 60.7 | 58.3 | 27.4 |
| RoBERTa-large | p-のみ検索 | 47.3 | 98.1 | 57.7 | 93.8 | 54.0 | 94.5 | 51.6 | 97.4 | 26.1 | 93.9 |
| RoBERTa-large | 普遍的トリガー最適化 | 91.9 | 93.7 | 89.2 | 86.7 | 88.7 | 90.1 | 83.1 | 94.3 | 80.4 | 94.2 |
| RoBERTa-large | + 段階的プロンプト毒化 | 93.7 | 96.7 | 88.3 | 95.2 | 88.4 | 95.9 | 83.4 | 98.0 | 82.9 | 98.6 |
| GPT2-large | τ + p 検索 | 68.8 | 54.0 | 67.3 | 59.2 | 68.4 | 60.7 | 58.2 | 59.6 | 49.9 | 24.2 |
| GPT2-large | p-のみ検索 | 48.3 | 96.1 | 51.1 | 91.5 | 56.1 | 93.7 | 50.0 | 93.4 | 27.0 | 94.5 |
| GPT2-large | 普遍的トリガー最適化 | 87.3 | 96.1 | 84.3 | 95.3 | 85.9 | 95.1 | 80.1 | 93.4 | 83.5 | 95.2 |
| GPT2-large | + 段階的プロンプト毒化 | 89.5 | 98.4 | 84.3 | 98.8 | 88.4 | 98.5 | 80.7 | 98.4 | 84.4 | 96.9 |
- TrojLLM は、タスクとモデル全体で高い攻撃成功率(ASR)と競合的または改善されたクリーン精度(ACC)を達成する。
- 普遍的トリガー最適化は、プロンプトのみの探索と比較して ACC を大きく改善する一方、固定種子トリガー探索により ASR は高いままである。
- 段階的プロンプト毒化はさらに ASR を増加させ、しばしば ACC を維持または向上させる。例:AG’s News では ASR が 98.6% に、ACC が 82.9% に上昇。
- 攻撃は PLM 間で良く転移し、小さなモデルのプロンプトが大きなモデルに適用されても ASR を維持または向上させ、ACC についても同様。
- 確率なし API では TrojLLM は平均 ASR が 93.70%、ACC が 88.60%、確率を用いる場合は 94.88% ASR と 90.28% ACC を達成。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。