[論文レビュー] TTN: A Domain-Shift Aware Batch Normalization in Test-Time Adaptation
TTNは従来のBNとテスト時BNの間をチャンネルごとに補間するドメインシフト対応BN層を導入し、ポストトレーニング段階で学習されるチャンネルごとの重みを用いて、様々なテスト時のバッチサイズやシナリオに対する頑健性を向上させ、追加の推論コストなしで既存のTTA手法を拡張可能。
This paper proposes a novel batch normalization strategy for test-time adaptation. Recent test-time adaptation methods heavily rely on the modified batch normalization, i.e., transductive batch normalization (TBN), which calculates the mean and the variance from the current test batch rather than using the running mean and variance obtained from the source data, i.e., conventional batch normalization (CBN). Adopting TBN that employs test batch statistics mitigates the performance degradation caused by the domain shift. However, re-estimating normalization statistics using test data depends on impractical assumptions that a test batch should be large enough and be drawn from i.i.d. stream, and we observed that the previous methods with TBN show critical performance drop without the assumptions. In this paper, we identify that CBN and TBN are in a trade-off relationship and present a new test-time normalization (TTN) method that interpolates the statistics by adjusting the importance between CBN and TBN according to the domain-shift sensitivity of each BN layer. Our proposed TTN improves model robustness to shifted domains across a wide range of batch sizes and in various realistic evaluation scenarios. TTN is widely applicable to other test-time adaptation methods that rely on updating model parameters via backpropagation. We demonstrate that adopting TTN further improves their performance and achieves state-of-the-art performance in various standard benchmarks.
研究の動機と目的
- 実用的なドメインシフトやバッチサイズの変動に対して、頑健なテスト時適応を動機づける。
- TTAにおける従来のBNと転導的BNのトレードオフに対処する。
- 事前学習済み重みを変更せずにチャンネルごとの補間重みを学習するポストトレーニング段階を開発する。
- 分類とセマンティックセグメンテーションのベンチマークにおいて、既存のTTA手法とTTNが互換性を示す。
提案手法
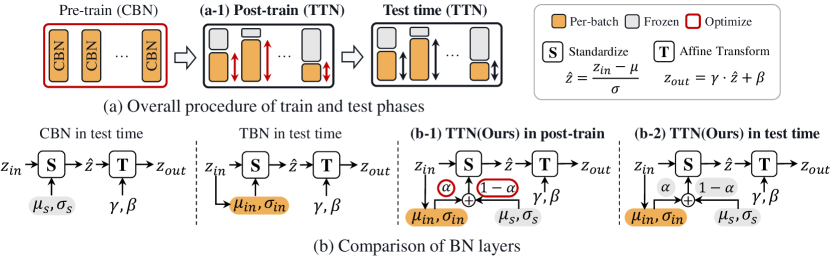
- TTNを、ソース(CBN)とテスト(TBN)バッチ統計の各チャネルごとの補間として、チャネルごと alphaを用いて定義する。
- tilde{mu}=alpha mu +(1-alpha) mu_s および tilde{sigma}^2 = alpha sigma^2 +(1-alpha) sigma_s^2 + alpha(1-alpha)(mu-mu_s)^2として tilde{統計量}を導出する。
- ドメインシフト感度から層/チャネルごとの事前アルファを推定するポストトレーニング段階を導入し、基底重みを凍結したままCEとMSE損失でalphaを最適化する。
- クリーン入力と増強入力下でBNアフィンパラメータの勾配から、勾配ベースのドメインシフト距離スコア d^{(l,c)} を計算し、alpha初期化の事前分布 A を導出する。
- ポストトレーニング中はBNをTTNに置換し、テスト時にはalphaを固定してソース知識を保持しつつターゲットドメインへ適応する。
- 既存の正規化ベースまたは最適化ベースのアプローチの上にTTNを適用して、他のTTA手法との互換性を示す。
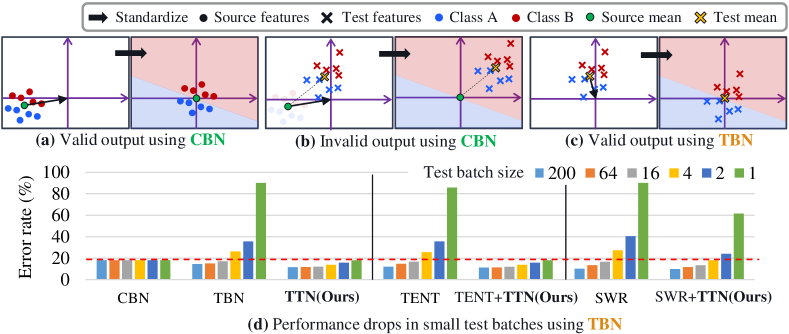
実験結果
リサーチクエスチョン
- RQ1ソースとテストのバッチ統計をチャネルごとに補間することは、変動するバッチサイズの下でTTAにおけるドメインシフトへの頑健性を向上させるだろうか?
- RQ2テスト前に補間重みを学習するポストトレーニング段階は、画像分類およびセマンティックセグメンテーションのベンチマークで一貫した利得を生むだろうか?
- RQ3定常・連続的変化・混合ドメイン適応下で、TTNは既存の正規化ベースおよび最適化ベースのTTA手法に比べてどう機能するか?
- RQ4TTNは見たことのないターゲット分布へ適応しつつ、ソースドメインの知識を保持できるか?
主な発見
- TTNは、さまざまなテストバッチサイズ(200から1まで)および複数の適応シナリオで、既存の正規化ベースBNアプローチを上回る。
- 既存のTTA手法にTTNを適用すると追加の利得が得られ、特に小さなバッチサイズや継続的・混合ドメイン適応で効果が大きい。
- TTNは純粋なテストバッチ統計法よりソースドメインの知識をより良く保持し、ドメインが異なる場合の劣化を軽減する。
- チャネルごとの補間重みは、浅い層がTBNから、深い層がCBNにより依存する傾向があり、ドメインシフトの特性と一致することを示す。
- ポストトレーニングで学習された固定のTTN混合比は、事前学習済み weightsを変更することなく、評価設定全体で効果を維持する。
- TTNはドメインシフトベンチマークにおけるセマンティックセグメンテーションの一般化性能も向上させ、TENTやSWRなどの手法を補完する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。