[論文レビュー] Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tulu 3 は、データ、コード、および評価を含む大規模言語モデルのオープンで完全に公開されたポストトレーニングレシピを提示し、RLVR などの手法を用いて 70B でオープンウェイトの同業他者や対抗するクローズドモデルを上回ることができることを示します。
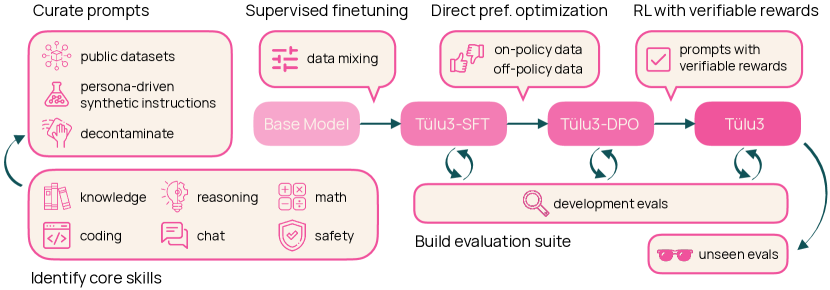
Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce Tulu 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. Tulu 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With Tulu 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the Tulu 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the Tulu 3 approach to more domains.
研究の動機と目的
- 独自手法との差を埋めるための完全にオープンなポストトレーニングフレームワークを定義する。
- 大規模 LLM の再現可能なポストトレーニングのために、オープンなデータセット、評価スイート、トレーニングレシピを提供する。
- オープンなポストトレーニングが最先端のオープンモデルを凌駕し、いくつかのクローズドモデルの機能に匹敵できることを示す。
- 複数のタスクに跨るコアスキルを向上させる新しいトレーニング段階とデータ戦略を導入・検証する。
提案手法
- Tulu 3 のデータ、評価、コードのエコシステムを説明する。
- SFT、直接的嗜好最適化(DPO)、検証可能な報酬による強化学習(RLVR)を含む多段階のトレーニングレシピを提案する。
- 進捗を測定・指針とするための広範なデコンタミネーションと評価ツールの開発。
- オンポリシーの嗜好データと検証可能な報酬信号を用いて、推論、数学、コーディング等のスキル開発を最適化する。
- オープンモデルとクローズドモデルを比較評価して相対的な性能を確立する。
実験結果
リサーチクエスチョン
- RQ1同程度のサイズの現代のオープンウェイトのポストトレーニングモデルと比べて、オープンで完全に公開されたポストトレーニングレシピが上回ることができるか?
- RQ2RLVR は数学や正確な指示従いといったスキルの検証可能な改善をもたらすか?
- RQ3開発中および未知のタスク全体で、どのデータ、方法論、評価実践がコアスキルを最も確実に向上させるか?
- RQ4デコンタミネーション済みの、合成データ、嗜好ベースデータをオープンなインフラと組み合わせることで、クローズドモデルの能力にどの程度匹敵できるか?
- RQ5完全にオープンなポストトレーニングパイプラインの実務的な設計上の考慮事項と制限は何か?
主な発見
- Tulu 3 モデルは、同サイズのオープンウェイト SOTA ベースラインを上回る。例として Llama 3.1 Instruct、Qwen2.5 Instruct、Mistral-Instruct など。
- 70B では、Tulu 3 は Claude 3.5 Haiku や GPT-4o mini などの一部クローズドモデルの機能と同等となる。
- Tulu 3 のパイプラインは SFT、DPO、RLVR を組み合わせ、コアスキル全般で高い性能を達成する。
- 広範なデコンタミネーションと堅牢な評価フレームワークはベンチマーク結果の信頼性を向上させる。
- リリースにはモデルウェイト、データ、コード、再現と適応を可能にするエンドツーエンドのレシピが含まれる。
- RLVR の新しい RL 目的は報酬が検証可能であることを保証し、スキル別の改善を導く。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。