[論文レビュー] Turning large language models into cognitive models
著者らは心理データで大規模言語モデル(LLaMA)をファインチューニングし、CENTaURを作成。認知モデリングシステムで人間の選択を予測し、新しいタスクへ一般化可能、意思決定領域で従来の認知モデルを上回り、個人差を捉える。
Large language models are powerful systems that excel at many tasks, ranging from translation to mathematical reasoning. Yet, at the same time, these models often show unhuman-like characteristics. In the present paper, we address this gap and ask whether large language models can be turned into cognitive models. We find that -- after finetuning them on data from psychological experiments -- these models offer accurate representations of human behavior, even outperforming traditional cognitive models in two decision-making domains. In addition, we show that their representations contain the information necessary to model behavior on the level of individual subjects. Finally, we demonstrate that finetuning on multiple tasks enables large language models to predict human behavior in a previously unseen task. Taken together, these results suggest that large, pre-trained models can be adapted to become generalist cognitive models, thereby opening up new research directions that could transform cognitive psychology and the behavioral sciences as a whole.
研究の動機と目的
- ドメイン特化の行動データを活用して、大規模言語モデルをドメイン全般にわたる認知モデルへ変換することを動機づける。
- 心理データで大規模言語モデルをファインチューニングすることで、正確で人間のような意思決定表現が得られることを示す。
- ファインチューニング済みモデルの埋め込みが、行動の個人差を捉えることを示す。
- 2つのタスクで学習したモデルを、ホールドアウトの3つ目のタスクで評価して一般化を検証する。
提案手法
- LLaMA(65Bパラメータ)を用い、心理実験を記述したプロンプトから埋め込みを抽出する。
- LLaMAの埋め込みの上に線形層をファインチューニングして人間の選択を予測する(CENTaUR)。
- ベースライン(ランダム、生データのLLaMA、BEAST、Gershmanハイブリッド)と比較して、100倍交差検証で予測性能を評価する。
- 記述からの選択肢(choices13k)と経験的実験(horizon task)から学習し、ホールドアウトタスクの性能を評価する。
- モデルの挙動をシミュレーションして、後悔(regret)と選択曲線を人間データと比較する。
- ファインチューニング層に参加者ごとのランダム効果を許可して個人差を捉える。
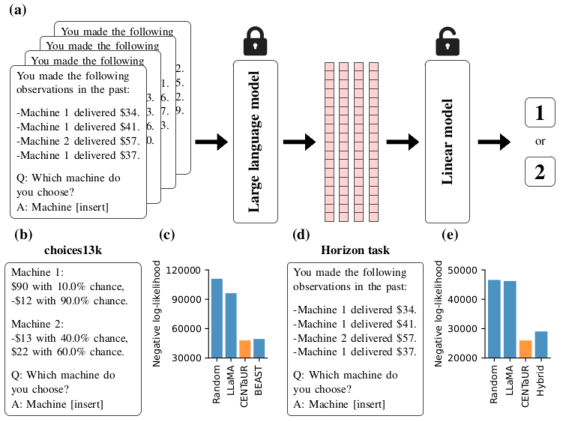
実験結果
リサーチクエスチョン
- RQ1大規模言語モデルの埋め込みをファインチューニングすることで、人間の意思決定を正確にモデル化できるか。
- RQ2CENTaURの埋め込みは、個々の被験者レベルの行動をモデル化するのに十分な情報を含んでいるか。
- RQ3複数のタスクでファインチューニングしたモデルは、事前に見ていないタスクで人間の行動を予測できるか。
- RQ4 CENTaURは領域特化の認知モデルとどう比較されるか。
主な発見
- CENTaURはchoices13kでNLL 48002.3を達成し、BEAST (49448.1)を上回った。
- CENTaURはhorizonタスクでNLL 25968.6を達成し、ハイブリッドモデル (29042.5)を上回った。
- ホールドアウトの経験的-象徴タスクでは、CENTaURはNLL 4521.1、ランダム (5977.7) および LLaMA (6307.9) より良かった。
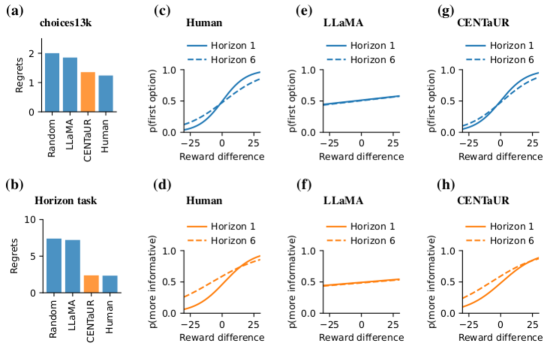
- シミュレーションでは、CENTaURの後悔(1.35、SE 0.01)は人間(1.24、SE 0.01)に近く、LLaMA(1.85、SE 0.01)より近かった。
- CENTaURは人間のような選択曲線を捉え、情報が等しい場合と異なる場合の探索効果を再現した。LLaMAとは異なる。
- 埋め込みベースのモデルは個人差をよく説明した。参加者ごとのランダム効果を加えると適合が向上した(NLL 23929.5 対 25968.6)。
- 2つのタスクでファインチューニングしたモデルが第3のホールドアウトタスクに一般化し、新しいパラダイムで人間の行動を予測した。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。